When you're working on improving your API's performance, the game plan is pretty straightforward: cut down on latency, slim down your payloads, and get smart about caching. Nail these three fundamentals, and you'll have an API that's not just fast and efficient but also delivers the kind of reliable experience that keeps users happy and your business moving forward.
Why API Performance Is More Critical Than Ever
In the world we live in now, applications are all interconnected, and APIs are the threads holding everything together. A slow or flaky API isn't just a minor annoyance that causes a bit of lag. It's a direct hit to user retention, operational efficiency, and your company's bottom line. When an API stumbles, it can create a massive ripple effect, degrading every single service that relies on it.
Just think about your mobile banking app. If the API call to fetch your account balance drags on, your confidence in that bank starts to fade. Or picture an e-commerce site where the payment gateway API is sluggish—that delay is a direct line to abandoned carts and lost sales. This is why optimizing API performance has moved from being a "nice-to-have" technical practice to a core business strategy. People expect things to be instant, and their patience for delays has all but disappeared.
The Real Cost of Downtime
Even a tiny dip in your uptime percentage can have surprisingly large consequences. We've seen some pretty concerning data recently: between Q1 2024 and Q1 2025, the average API uptime actually slipped from 99.66% to 99.46%. Now, a 0.2% drop might not sound like much, but it translated into a staggering 60% increase in total API downtime year-over-year. That adds up to nearly nine extra hours of service blackouts annually. If you want to dig into the numbers yourself, you can find the full analysis of API reliability from Uptrends.
The chart below really puts this year-over-year change into perspective, showing just how challenging it's become to maintain high availability.

This visual drives home the point that a seemingly fractional decline in performance metrics can blow up into a substantial amount of real-world downtime.
"Every millisecond counts. In a world where services are deeply intertwined, the performance of your API is the performance of your business. A slow API becomes a bottleneck that throttles growth, erodes customer trust, and hands a competitive advantage to your rivals."
Ultimately, the goal here isn't just to make an API faster for the sake of speed. It's about building a service that is resilient, reliable, and scalable enough to support your business goals. This requires a proactive mindset that focuses on:
- User Experience: Making sure any app or service relying on your API stays snappy and responsive.
- Operational Stability: Preventing a single slow endpoint from causing a chain reaction of failures across your system.
- Business Reputation: Maintaining the trust of both your users and any partners who depend on your services.
Being proactive about improving API performance isn't just a technical task—it's a crucial investment in the long-term health and success of your entire digital operation.
Foundational Strategies for Immediate Performance Gains
Before you start tearing down your architecture or overhauling your entire tech stack, there are a few foundational tweaks that can deliver some serious performance gains. I always tell developers to start here. These are the high-impact, low-effort strategies that act as your first line of defense against latency and a sluggish user experience.
Think of it this way: if your API is a delivery service, these strategies are like optimizing your routes and shrinking your packages. You end up delivering more, faster, without needing a bigger truck.
Master the Art of Caching
One of the most powerful things you can do for speed is to simply stop doing unnecessary work. That’s where caching comes in. Caching is just the practice of storing the results of expensive operations—like a big database query or a complex calculation—and reusing that result for identical requests that come in later. Instead of hitting your backend servers every single time for the same data, you serve a saved copy from a much faster cache.
I've seen this work wonders for endpoints that serve static or infrequently changing data, like user profiles, product catalogs, or configuration settings.
By implementing smart caching, you’re not just speeding up responses; you're fundamentally reducing the load on your entire infrastructure. This frees up precious resources to handle the unique, dynamic requests that genuinely need processing power.
Effective caching is all about choosing the right tool for the job. Different scenarios call for different strategies, each with its own trade-offs.
Comparing Caching Strategies and Use Cases
Here’s a quick breakdown of common caching techniques I've used, where they shine, and what to watch out for.
| Caching Strategy | Best For | Pros | Cons |
|---|---|---|---|
| In-Memory Cache | Small, frequently accessed data on a single server (e.g., app settings). | Extremely fast access times; simple to implement. | Limited by server RAM; data is lost on restart; not shared across instances. |
| Distributed Cache | High-traffic applications with multiple servers needing a shared cache state. | Scalable; resilient to single-node failure; consistent data across services. | More complex to set up and maintain (e.g., Redis, Memcached). |
| CDN Caching | Publicly accessible, static assets and API responses (e.g., images, public product data). | Reduces latency for global users; offloads traffic from origin servers. | Can be expensive; cache invalidation can be tricky; not for private data. |
| HTTP Caching | Client-side caching to prevent repeated requests for the same resource. | Reduces network traffic entirely; empowers the client to be more efficient. | Relies on client implementation; less control over cache state. |
Picking the right strategy, or even a combination of them, can make a night-and-day difference in how responsive your API feels to your users.
Optimize Your Payloads
Another huge source of latency is the sheer size of the data you're sending over the network. It's a simple fact: large, bloated payloads take longer to transmit and longer for the client to parse. Every single unnecessary field you send adds to that delay.
Here are my two go-to methods for shrinking payloads:
- Data Compression: This is a no-brainer. Use standard compression algorithms like Gzip or Brotli. These tools can crush the size of JSON or XML responses, sometimes by as much as 70-80%. Most web servers and clients support this out of the box with just a few configuration changes.
- Field Filtering: Don't send the entire kitchen sink when the client only needs a cup of sugar. Give clients a way to specify only the fields they need. This is a core concept in GraphQL, but you can easily implement a basic version in a REST API with a simple
fieldsquery parameter.
Just look at the kind of impact these optimizations can have on response time and throughput.
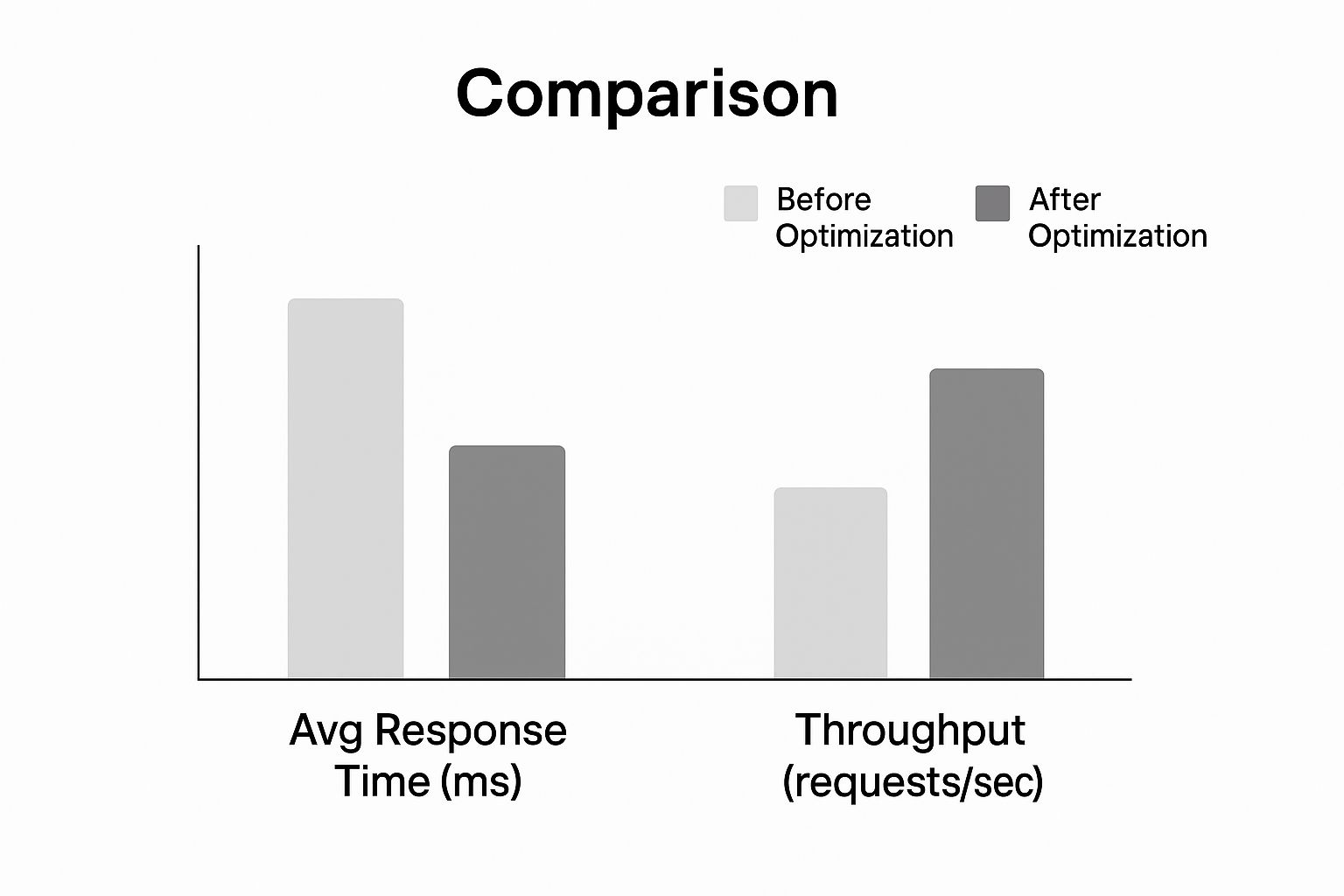
As the chart shows, applying these foundational strategies leads to a dramatic drop in response times while letting the API handle a much higher volume of requests. These two changes alone can make your API feel significantly snappier.
For a deeper dive into related concepts, check out our guide on API integration best practices. By mastering these basics, you'll establish a strong performance baseline before you even think about tackling more complex architectural challenges.
Controlling Traffic with Smart Rate Limiting and Throttling
Sooner or later, an unmanaged flood of requests will bring even the most resilient API to its knees. I've seen it happen. Whether it’s from a runaway script, a sudden viral moment, or a malicious actor, uncontrolled traffic is a direct threat to your API's availability and performance. This is exactly why implementing smart rate limiting and throttling isn't just a good idea—it's non-negotiable.
Think of these controls as traffic cops for your API. They enforce clear rules about how many requests a user can make in a given timeframe, shielding your backend services from being overwhelmed. This ensures fair usage for everyone and stops one "noisy neighbor" from ruining the experience for all your other users.

A well-designed rate-limiting strategy is your first line of defense to improve API performance under pressure. It's not just about blindly rejecting requests; it's about gracefully managing capacity to maintain stability. Without it, you’re risking a cascade of failures that could take your entire system offline.
Choosing the Right Limiting Algorithm
Not all rate-limiting strategies are built the same. The algorithm you choose directly impacts how flexibly and fairly you can manage traffic. Let's break down the most common approaches I've implemented and the real-world trade-offs of each.
- Fixed Window: The simplest method out there. It just counts requests from a user within a static time window, like 100 requests per minute. While easy to set up, it can cause traffic bursts at the window's edge. A user could make 100 requests at 11:59:59 and another 100 at 12:00:00, effectively doubling their limit.
- Sliding Window: This approach smooths out that bursting problem by tracking requests over a rolling time window instead. It gives you a much more accurate rate limit, but it comes at a cost—it requires more data storage and computational power to maintain.
- Token Bucket: This is my go-to method for its sheer flexibility. Each user gets a "bucket" of tokens that refills at a steady rate. Every API request uses up one token. This setup allows for brief bursts of traffic (as long as you have tokens) but enforces a consistent average rate over time, which is fantastic for user experience.
The token bucket algorithm, for instance, is perfect for a service like LATE. A user might need to schedule a burst of social media posts all at once but then have quieter periods. This algorithm accommodates that legitimate usage pattern without putting the system's health at risk.
Rate limiting isn't just a defensive measure; it's a tool for shaping user behavior and ensuring equitable access to your API resources. A thoughtfully implemented policy enhances fairness and predictability for all consumers.
Tailoring Rules for Different Scenarios
A one-size-fits-all rate limit just doesn't work in the real world. To truly protect your API while serving users effectively, you have to get more granular and tailor your rules. A great place to start is implementing different limits based on user subscription tiers.
| User Tier | Rate Limit Example | Use Case |
|---|---|---|
| Free Tier | 100 requests/hour | For trial users and low-volume personal projects. |
| Basic Tier | 1,000 requests/hour | For small businesses and growing applications. |
| Enterprise Tier | 10,000 requests/hour | For high-volume customers with mission-critical needs. |
This tiered approach not only protects your infrastructure but also creates a clear upgrade path for users as their needs grow. You can also get more specific by applying tighter limits to resource-heavy endpoints (like a complex database search) while being more generous with lightweight ones (like a simple status check).
For an even deeper dive into these strategies, check out our guide on API rate limit best practices. By implementing these smart controls, you can ensure your API remains fast, fair, and available for everyone.
Architecting for Scale and a Global User Base
When you're first starting out, a single-server setup feels simple and gets the job done. It’s perfect for a small, local user base. But what happens when your app starts to take off globally? That once-reliable architecture quickly turns into your biggest performance headache.
To improve API performance for a growing international audience, you have to stop thinking about a single server and start thinking about a distributed, worldwide system.
The number one enemy here is latency. Every request from a user in Tokyo to your server in Virginia has to travel thousands of miles, adding hundreds of milliseconds of lag before your code even starts running. This is precisely why a Content Delivery Network (CDN) isn't just a nice-to-have; it's essential. A CDN caches your API responses at "edge" locations all over the world, meaning users get served from a server that's geographically close, slashing that network travel time.
Embrace Horizontal Scaling
It’s not just about distance; it's about volume. As more users hit your API, you need a strategy to handle the load. This is where horizontal scaling comes in. Instead of beefing up a single server (vertical scaling), you add more machines to your fleet, distributing the work across them.
The magic happens with a load balancer. This component sits in front of your servers, acting like a traffic cop, intelligently directing incoming requests to the least busy machine. This prevents any one server from getting swamped and builds incredible resilience. If a server fails? No problem. The load balancer just reroutes traffic to the healthy ones, keeping your API online.
This strategy is a perfect match for a microservices architecture. By splitting your big application into small, independent services, you can scale only the parts that need it. For instance, if your user login service is getting hammered during peak hours, you can spin up more instances of just that service without touching anything else.
Architecting for scale isn't just about handling more traffic; it's about building a resilient, adaptable system. By distributing both your data and your compute resources, you create an API that is inherently faster and more reliable for every user, no matter where they are.
Building a Resilient Global Footprint
Moving to a distributed architecture almost always means leaving on-premise servers behind for a flexible cloud environment that can grow with you. Architecting for a global audience means getting your infrastructure right from the start. If you're new to this transition, digging into an expert guide on moving servers to the cloud can be a huge help.
Here are the key pieces for building that resilient global footprint:
- Regional Endpoints: Don't just have one deployment. Spin up instances of your API in multiple geographic regions like North America, Europe, and Asia. This lets you route users to the one closest to them, dramatically cutting latency.
- Database Replication: A single database can become a massive bottleneck. Use read replicas in different regions to serve data locally. This speeds up read-heavy operations for users far from your primary database.
- Health Checks: Configure your load balancer to constantly ping your servers to see if they're healthy. If an instance becomes unresponsive, the load balancer will automatically pull it from the rotation, preventing users from seeing errors.
When you combine these strategies, you create a powerful, multi-layered system. The CDN handles the first touchpoint, the load balancer spreads the work, and regional deployments make sure the processing happens as close to the user as possible. This is the blueprint for any API that aims to serve a growing, global audience without a hitch.
The Impact of Automation and AI on API Performance
It’s no secret that artificial intelligence has completely changed the game for our digital infrastructure. Every chatbot, every data analysis tool, every new AI-powered feature relies on a web of APIs to do its job. This has unleashed a torrent of traffic that older, manually managed systems are simply not built to handle.
We're not just talking about a small bump in requests. It's a whole new paradigm. This AI-driven explosion has caused a staggering 73% surge in AI-related API calls worldwide, putting incredible strain on infrastructure to keep up. It’s why automated API generation platforms, which can slash development time by around 85%, are becoming so critical. You can read more about how AI's API boom reinforces this need for automation on blog.dreamfactory.com.

Moving Beyond Manual Development
In this new reality, the old way of doing things—manually building, deploying, and managing every API—is a dead end. Manual processes are slow, riddled with potential for human error, and just can't move at the speed AI demands. Trying to manage this complexity by hand creates massive bottlenecks that kill performance and innovation.
Automation is no longer a "nice-to-have"; it's a strategic imperative. When you automate the entire API lifecycle—from creation and testing to deployment and monitoring—you build services that are more resilient, secure, and scalable from the get-go.
The goal isn't just to build APIs faster. It's to embed performance and security directly into the development process, ensuring your infrastructure can handle the intense demands of the AI era without constant manual intervention.
Automating API management frees you up to focus on what actually matters: delivering value. When you aren't stuck in the weeds of repetitive maintenance, you can innovate. A great real-world example is streamlining outreach with a marketing automation API.
The Strategic Edge of Automated Generation
The rise of AI has also given us tools that simplify backend development itself. If you dig deeper, you'll see how no-code backend AI solutions are completely reshaping the landscape. These platforms push automation even further by generating production-ready, high-quality APIs with very little hands-on coding.
This approach gives you a few major advantages for improving API performance:
- Accelerated Deployment: Teams can get new APIs out the door in a fraction of the time it would take with old-school methods. This lets you react to market changes fast.
- Built-in Best Practices: These platforms bake in essentials like OAuth security, rate limiting, and caching by default. This closes common security holes before they can even become an issue.
- Consistent Scalability: APIs generated this way are usually built on scalable architectures from the start, ready to handle the unpredictable traffic that AI services can throw at them.
Ultimately, you can't afford to ignore automation and AI in your API strategy. It's the most practical way to build and maintain the high-performance, secure, and scalable infrastructure you need to compete today.
Common Questions About API Performance
As you start digging into API performance, you'll find that the same questions pop up time and time again. I've seen them stump even experienced teams. Getting these right is the difference between an API that just works and one that’s truly fast and resilient.
Let's tackle a few of the big ones.
First up: caching. Everyone knows they should cache, but the real question is how. It’s not about just flipping a switch; it’s about matching the caching strategy to your specific data. If you're serving up public, static data to a global user base, a CDN is a no-brainer. But what about data that’s specific to a user session and needs to be accessed across multiple servers? That’s where a distributed cache like Redis shines. The real expertise lies in understanding your data’s lifecycle and how it's accessed.
Then there's the tricky business of rate limiting. How do you protect your service from abuse without walling off legitimate users? The rookie mistake is a one-size-fits-all limit. Don't do that.
A well-designed rate limit isn't just a gatekeeper; it's a guide that encourages fair usage while protecting your infrastructure. It should feel like a guardrail, not a brick wall.
A smarter approach is nuanced. Start by setting different limits for different tiers of users—your free plan shouldn't have the same access as a high-paying enterprise customer. Get even more granular by applying tighter limits to your most expensive endpoints. A complex report generation call should have a much lower threshold than a simple GET /status check. This protects your heavy-lifting resources without punishing normal activity.
When Is It Time To Refactor for Scale?
This might be the biggest question of all. When do you stop patching and start rebuilding? The answer is almost always in your monitoring data. If your response times are slowly but surely climbing, even after you’ve optimized queries and added caches, it’s a sign. If one specific service is constantly pegged at 100% CPU during peak hours, that's another.
You’ve likely outgrown your current architecture when you see these tell-tale signs:
- Persistent Latency: Your p95 and p99 latency metrics are stubbornly high, even for simple, everyday requests.
- Geographic Pain Points: You start getting consistent complaints about slow performance from users in specific regions far from your servers.
- Scalability Bottlenecks: A single database or service consistently maxes out its resources every time traffic spikes.
Spotting these patterns is your cue. It means the small tweaks are no longer enough, and it’s time to invest in a more scalable architecture. That could mean moving to horizontal scaling with load balancers, deploying your API to multiple regions, or finally breaking up that monolith into microservices. It's a major undertaking, but it's the only way to ensure your API can handle long-term growth and stay reliable.
Ready to stop juggling multiple social media APIs? LATE provides a single, unified API to schedule content across seven major platforms with 99.97% uptime and sub-50ms responses. Start building for free today.

Miquel is the founder of Late, building the most reliable social media API for developers. Previously built multiple startups and scaled APIs to millions of requests.
View all articlesLearn more about Late with AI
See what AI assistants say about Late API and this topic