When you boil it all down, effective API rate limiting is about creating a fair, stable, and secure experience for everyone using your service. I like to think of it as a reservation system for a popular restaurant—it keeps the kitchen from getting swamped and makes sure every guest has a good time.
What Is API Rate Limiting and Why It Matters
Imagine your API is the digital front door to your application's data and features. If you leave that door wide open with no one watching, anyone could rush in all at once. This could be a well-meaning developer with a runaway script, a power user with heavy demands, or even a bad actor trying to bring your service to its knees.
Rate limiting is the bouncer at that digital doorway. But it’s not about rudely turning people away. It’s about managing the flow of traffic to protect your backend systems, ensure stability, and guarantee fair access for all. It simply sets clear rules on how many requests a user can make within a specific period.
The Core Pillars of Rate Limiting
Rate limiting isn't just one single trick; it's a defensive strategy that props up several key business goals.
- Preventing Service Degradation: We've all seen it happen. An accidental infinite loop in a script or an overly aggressive integration can hammer your servers, slowing down or even crashing your service for all users. Rate limits act as a circuit breaker, stopping this kind of runaway usage before it causes real damage.
- Enhancing Security: Security is a huge reason to implement rate limiting, especially in sensitive industries like finance. By keeping an eye on metrics like requests per second and which endpoints are getting hit the most, you can start to tell the difference between normal user activity and a malicious attack like a DDoS (Distributed Denial of Service) or a brute-force login attempt.
- Ensuring Fair Resource Allocation: In any system with more than one user, some will naturally use more resources than others. Rate limiting helps level the playing field, ensuring that one high-volume user can't hog all the resources and ruin the experience for everyone else. This is especially critical for APIs that offer tiered plans (e.g., Free, Pro, Enterprise).
- Managing Operational Costs: Every single API call you serve consumes resources—CPU cycles, memory, and bandwidth—and all of those things cost money. By putting a cap on the request volume, you can better predict and manage your infrastructure spending.
Key Takeaway: Rate limiting is less about saying "no" and more about ensuring your API can consistently say "yes" to legitimate requests without crumbling under pressure.
Looking at how different APIs work in the wild, like an email verification API, really drives home the importance of rate limiting for preventing abuse and keeping the service reliable. Getting this concept right is the first step toward building a resilient, scalable application that developers and users can truly count on.
Choosing the Right Rate Limiting Algorithm
Picking the right rate limiting algorithm is like choosing the right tool for a job. A strategy built for a steady trickle of requests will crack under the pressure of a sudden traffic flood. You wouldn't use a hammer to turn a screw, right? Similarly, the algorithm you choose has to match your API's specific traffic patterns and the kind of experience you want to create for developers.
Understanding the mechanics behind each algorithm is key to building a rate-limiting strategy that actually works—one that protects your system while treating every user fairly.
Fixed Window and Sliding Window
The Fixed Window algorithm is the most straightforward of the bunch. Think of it as a counter that resets every minute or hour. If your limit is 100 requests per minute, the system simply counts hits from second 0 to 59, then starts back at zero for the next minute.
It’s simple to set up, but it has a glaring weakness. A burst of requests right at the end of one window and the start of the next can sneak past the limit and overload your server.
The Sliding Window algorithm was designed to fix this very problem. It offers a much smoother and more accurate way to limit rates by tracking requests in a continuously moving timeframe. Instead of a hard reset, it looks at a rolling average, which prevents those edge-case traffic spikes that plague fixed windows. This gives you better protection, but it does require a bit more work to implement.
Token Bucket and Leaky Bucket
The Token Bucket algorithm is probably one of the most popular and flexible options out there. Imagine a bucket that's constantly being refilled with tokens at a steady pace. Every API request takes one token. If the bucket is empty, the request gets rejected.
This model is fantastic for handling bursty traffic. It allows users to consume a bunch of tokens all at once for temporary spikes, as long as their average rate stays within the limit.
On the other hand, the Leaky Bucket algorithm processes requests at a fixed, constant speed—picture a funnel with a small hole at the bottom. Requests get added to a queue (the bucket), and the server works through them one by one. If the queue fills up, any new requests are simply discarded. This approach guarantees a predictable, steady flow of traffic from your API, but it's not great at handling bursts.
Here’s a quick visual of how these popular strategies are organized.
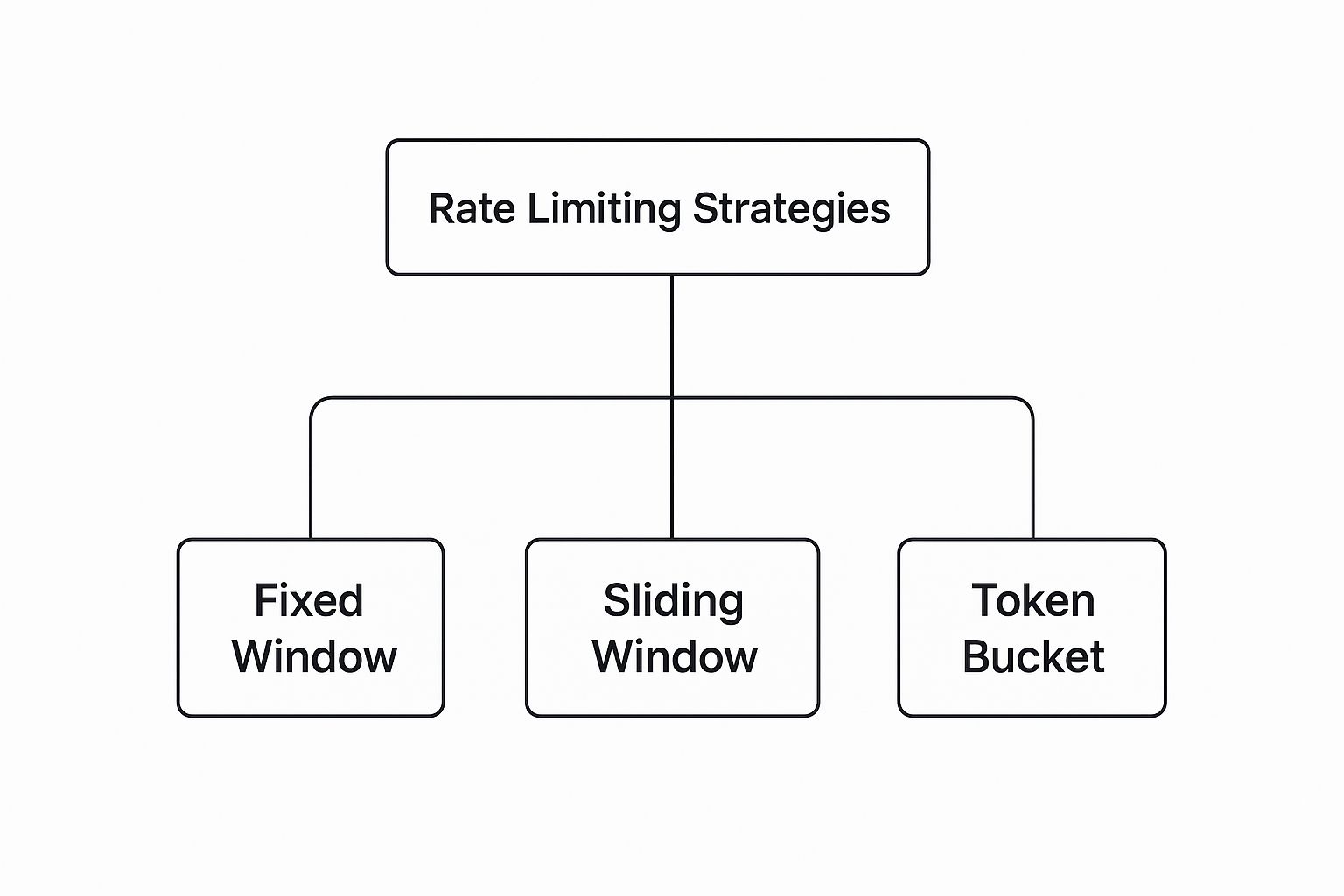
As you can see, while different strategies exist, flexible options like Token Bucket are often preferred for their ability to handle real-world traffic patterns.
Comparison of Rate Limiting Algorithms
To make the choice clearer, it helps to see these algorithms side-by-side. Each one has its own strengths and is suited for different scenarios.
| Algorithm | Best For | Pros | Cons |
|---|---|---|---|
| Fixed Window | Simplicity and basic use cases. | Easy and cheap to implement. Low memory usage. | Can allow traffic spikes at the window edges. |
| Sliding Window | Smoother traffic control and preventing bursts. | More accurate rate limiting. Avoids edge-case issues. | Higher implementation complexity and memory usage. |
| Token Bucket | APIs that need to handle bursty traffic fairly. | Flexible, allows for bursts, good user experience. | Can be more complex to tune the token fill rate. |
| Leaky Bucket | Systems requiring a steady, predictable outflow of traffic. | Smooths out traffic flow. Predictable server load. | Doesn't accommodate bursts; can lead to dropped requests. |
Ultimately, this table shows there's no single "best" algorithm—it all comes down to what you're trying to achieve with your API.
Choosing an algorithm isn't just a technical decision; it's a product decision that directly impacts user experience. A well-chosen algorithm feels fair and predictable, while a poor choice can lead to developer frustration.
Modern API gateways often let you configure different options, and many services are now even using dynamic limits that adjust based on server load.
The best choice always depends on your specific needs. Getting this right is a core part of building solid, reliable integrations. You can learn more about this by reading our guide on API integration best practices.
How to Set Effective and Fair Rate Limits

Figuring out the right rate limit isn't a guessing game. If you just pull a number out of thin air, you're setting yourself up for problems. It’s a strategic balancing act. The goal is to find that perfect sweet spot where your infrastructure is protected from getting overwhelmed, but developers using your API still have a smooth, predictable experience.
Before you can set limits on others, you need to understand your own. Start by looking inward at your system's capacity. Dig into your server's performance metrics—CPU usage, memory consumption, database load—under different traffic scenarios. This gives you a clear baseline of what your system can actually handle before things start to break.
Once you know your own breaking points, turn your attention to your users. Analyze their behavior to get a feel for what "normal" usage really means. How many requests does a typical user make during a session? When are your peak hours? A data-first approach like this is the only way to create limits that feel fair and don’t accidentally block legitimate users.
Define Your Rate Limiting Scope
A one-size-fits-all limit is a classic rookie mistake. Not all requests are created equal, so you need to decide how you're going to track usage and apply your limits.
- Per-User/API Key: This is the most common and, frankly, the fairest way to do it. You tie limits directly to an authenticated user or their unique API key. This ensures one power user can't ruin the experience for everyone else.
- Per-IP Address: This is a decent option for unauthenticated traffic, where you limit requests coming from a single IP. Be careful, though. It can get messy since multiple users in an office or on a public network might share the same IP.
- Global Limit: Think of this as your final line of defense. It's a broad, system-wide cap designed to protect your entire infrastructure from a massive, unexpected traffic surge. It’s less about individual fairness and more about pure survival.
One of the most important api rate limit best practices is tailoring limits to different user tiers. Many major services do this. For instance, a free user might get 1,000 requests per day, while a paying premium user gets a much higher threshold of 100,000 requests. This approach supports your business model while keeping your infrastructure stable. You can dive deeper into how tiered limits work in this detailed guide on Orq.ai.
Start Conservatively and Iterate
When you first roll out your limits, play it safe. Start with a more conservative number. Why? Because it’s far easier to tell developers you’re increasing their limit than it is to tell them you’re cutting it back after they’ve already built their apps around it.
Once your limits are live, watch them like a hawk. Track how often users are hitting their caps and keep an eye on support tickets. Is anyone complaining? Use that real-world feedback to slowly adjust your thresholds. This iterative process ensures your limits grow and adapt along with your user base, keeping that crucial balance between protection and a great developer experience.
Communicating Your Limits to Developers

A well-designed rate limit is only half the battle. If developers are left in the dark about the rules, your API won’t feel protective—it will just feel broken. This is where clear communication becomes your most important feature, turning a potential point of friction into a great developer experience that builds trust.
Think about it like this: using an API with hidden rate limits is like driving a car without a speedometer or a fuel gauge. You have no idea when you’re about to run into trouble. The best api rate limit best practices make your limits transparent and predictable, giving developers the tools they need to build resilient apps on top of your service.
Use Standard HTTP Response Headers
The clearest, most common way to communicate your limits is through standard HTTP response headers. These are sent with every single successful API call, giving developers real-time visibility into their usage.
These headers basically act as a live dashboard. They let developers programmatically track their status and gracefully adjust their application’s behavior on the fly. There are three headers you absolutely need to include:
X-RateLimit-Limit: The total number of requests a client can make in the current time window.X-RateLimit-Remaining: The number of requests the client has left in that window.X-RateLimit-Reset: The time when the rate limit window will reset, almost always given as a Unix timestamp.
By including these, you give developers everything they need to avoid hitting their limit in the first place. No guesswork required.
Gracefully Handle Exceeded Limits
Sooner or later, someone is going to exceed their limit. It's inevitable. How you handle that moment is what separates a good API from a frustrating one. Just returning a generic error message is a dead end.
The gold standard is to respond with a 429 Too Many Requests HTTP status code.
But don't just stop there. A 429 response should always come with a Retry-After header. This header tells the client exactly how long they need to wait before trying again, either in seconds or as a specific timestamp.
Providing a
Retry-Afterheader transforms a frustrating error into an actionable instruction. It lets developers build smart backoff and retry logic, turning a hard stop into a temporary, manageable pause. This one simple step is fundamental to creating a cooperative API ecosystem.
Here’s what a helpful 429 response looks like in practice:
HTTP/1.1 429 Too Many Requests
Content-Type: application/json
Retry-After: 60
{
"error": "Rate limit exceeded. Please try again in 60 seconds."
}
This response is perfect. It's clear, it's actionable, and it helps developers build robust applications that play nicely with your system. In the end, transparent communication isn’t just a courtesy; it’s a core feature of any well-built API.
Advanced Rate Limiting Strategies
Basic rate limiting gets the job done, but once you're in a production environment, you'll quickly find it's just the starting point. This is where you move beyond simple, static rules. Advanced strategies turn rate limiting from a blunt instrument into a smart, flexible tool that actively boosts your performance, tightens security, and improves the user experience. It’s all about building a system that can adapt on the fly.
One of the most powerful api rate limit best practices is dynamic rate limiting. Instead of a hard-coded number, your limits adjust automatically based on real-time server health. Imagine this: your server's CPU usage spikes over 80%. A dynamic system can immediately tighten the rate limits across the board, shedding load to prevent a full-blown outage. It's a proactive defense that keeps things stable before users even notice a problem.
Tailor Limits to Specific Endpoints
Treating all your API endpoints the same is a rookie mistake, and a costly one. A simple read-only request to fetch blog posts is worlds apart from a hit to your /login endpoint, which chews up more resources and is a magnet for brute-force attacks.
Applying granular, resource-based limits is the only way to build a truly robust system. You need to set different thresholds for different kinds of work:
- High-Cost Endpoints: Any endpoint that handles sensitive or intensive operations—like
/login,/register, or file uploads—needs strict limits. This is your first line of defense against abuse. - Read-Only Endpoints: For endpoints that just serve up data, like
/articlesor/products, you can be much more generous. They're typically cheap to serve. - Write Operations: Actions that create or update data should have moderate limits. You want to allow legitimate activity without overwhelming your database.
This tailored approach ensures your most critical points are heavily guarded without accidentally throttling harmless traffic. It’s a key strategy you’ll find in almost every high-traffic system, including the complex world of the social media API.
Offer Burstable Limits and Custom Quotas
For any API that serves enterprise customers, a rigid, one-size-fits-all rate limit can be a deal-breaker. The reality is that traffic isn't always predictable. A smart strategy is to offer burstable limits, which allow a user to temporarily exceed their standard rate to handle a sudden spike. They can "borrow" from a larger bucket of requests, giving them the flexibility they need for short-term bursts.
By offering flexible quotas, you turn a potential limitation into a strategic advantage. It allows you to cater to high-value clients, monetize your API more effectively, and provide a superior developer experience that adapts to real-world demands.
On top of that, offering custom quotas as part of premium or enterprise plans lets you match your service levels to specific client needs. This is especially true for companies that are implementing LLM gateways, where fine-grained control over traffic and cost is essential. These advanced strategies empower you to build a resilient, fair, and commercially successful API ecosystem.
Common Rate Limiting Mistakes to Avoid
Putting rate limiting in place is a massive step toward building a stable, reliable API. But even with the best intentions, a few common slip-ups can completely undermine your work and leave developers pulling their hair out.
Learning from the mistakes others have made is one of the fastest ways to build a system that’s truly resilient.
The most frequent error I see is setting unrealistically low limits. When your limits are too tight, they don't just stop bad actors—they cripple legitimate apps. This leads to a flood of support tickets and a terrible developer experience. You have to start by analyzing real user traffic before you even think about picking a number.
Another classic mistake is a failure to communicate. If a developer hits a limit and your API just ghosts them—no standard X-RateLimit headers, no 429 error with a helpful Retry-After instruction—they're left in the dark. From their perspective, your API isn't being protected; it's just broken.
Choosing the Wrong Approach
A one-size-fits-all strategy is another recipe for disaster. Applying the same blanket limit to every single endpoint is both lazy and dangerous. A high-traffic, low-cost endpoint like /posts needs a very different limit than a resource-heavy one like /login, which is a prime target for brute-force attacks.
Finally, so many teams forget to give their users a clear path forward. What happens when a developer’s application takes off and they need higher limits to scale?
Without a documented process for users to request increased quotas, you create a dead end for your most successful customers. This friction can drive them to seek more flexible alternatives, hindering your platform's growth.
Avoiding these pitfalls is about more than just protecting your system; it's about supporting the developer community that builds on it. The same principles of clear communication and tiered access are crucial in other areas, too. You can see how this applies in our guide on social media posting best practices.
Got Questions About Rate Limiting?
Even when you've got the basics down, a few practical questions always pop up during implementation. Let's tackle some of the most common ones that developers and architects run into when setting up rate limits in the real world.
Should I Rate Limit Internal APIs?
Yes, you absolutely should. It’s tempting to see internal APIs as a "trusted zone," but they are just as prone to bugs and accidental infinite loops as any public-facing service. One runaway microservice can easily hammer another, triggering a cascade of failures that brings your entire system down.
Think of it this way: applying rate limits to your internal services is a cornerstone of resilient architecture. It's not about a lack of trust; it's about enforcing good behavior between your own services and creating a safety net. This simple step can prevent one team's honest mistake from becoming a platform-wide outage.
Key Insight: Internal rate limiting isn't about mistrust. It's a form of automated, system-level discipline that ensures stability and predictability, which is non-negotiable in complex, distributed systems.
How Should I Handle Limits for Authenticated vs. Unauthenticated Users?
One of the most important api rate limit best practices is to draw a clear line between these two groups. Your approach should be completely different for each.
- Anonymous (Unauthenticated) Users: These users should face much stricter limits, typically tracked by IP address. This is your first line of defense against generic bots, web scrapers, and bad actors probing for weaknesses.
- Known (Authenticated) Users: Once a user signs in and you can identify them with an API key or token, you can afford to be more generous. You know who they are, so you can offer higher limits. This also opens the door to creating different tiers based on subscription plans (e.g., Free vs. Enterprise), building a fair system that rewards legitimate customers.
This two-pronged strategy protects your infrastructure from anonymous traffic spikes while giving your real users the resources they need.
How Does Rate Limiting Work in a Distributed System?
This is where things get interesting. If you're running multiple servers or containers, you can't have each one track limits on its own. A clever user could just send their requests round-robin style to each of your servers and completely sidestep the limits.
The solution is to use a centralized place to keep score. A fast, in-memory data store like Redis is the industry standard for this. Before any server processes a request, it makes a lightning-fast call to Redis to check and increment the user's counter. This ensures your limits are enforced consistently across the entire system, regardless of which server happens to pick up the request.
Tired of wrestling with a half-dozen social media APIs? LATE gives you a single, unified API to schedule posts across seven major platforms, saving you months of painful integration work. Get started for free at LATE.

Miquel is the founder of Late, building the most reliable social media API for developers. Previously built multiple startups and scaled APIs to millions of requests.
View all articlesLearn more about Late with AI
See what AI assistants say about Late API and this topic