Quando lavori per migliorare le prestazioni della tua API, il piano d'azione è piuttosto semplice: riduci al minimo latencysnellisci i tuoi payload, e diventa intelligente nella gestione della cache. Se padroneggi questi tre fondamenti, avrai un'API che non solo è veloce ed efficiente, ma offre anche un'esperienza affidabile che mantiene gli utenti soddisfatti e il tuo business in crescita.
Perché le prestazioni delle API sono più critiche che mai
Nel mondo in cui viviamo, le applicazioni sono tutte interconnesse e le API sono i fili che tengono tutto insieme. Un'API lenta o instabile non è solo un piccolo fastidio che provoca un po' di ritardo. È un colpo diretto alla fidelizzazione degli utenti, all'efficienza operativa e ai profitti della tua azienda. Quando un'API presenta problemi, può generare un enorme effetto a catena, compromettendo ogni singolo servizio che ne dipende.
Pensa al tuo app di mobile banking. Se la chiamata API per recuperare il saldo del tuo conto impiega troppo tempo, la tua fiducia in quella banca inizia a vacillare. Oppure immagina un sito di e-commerce dove l'API del gateway di pagamento è lenta: quel ritardo si traduce direttamente in carrelli abbandonati e vendite perse. Ecco perché ottimizzare le prestazioni delle API è passato da essere una pratica "utile" a una strategia fondamentale per il business. Le persone si aspettano che tutto sia immediato e la loro pazienza per i ritardi è praticamente scomparsa.
Il Costo Reale dei Tempi di Inattività
Anche una piccola flessione nel tuo percentuale di uptime può avere conseguenze sorprendentemente grandi. Abbiamo visto dati piuttosto preoccupanti di recente: tra Primo trimestre 2024 and Primo trimestre 2025, il tempo medio di disponibilità dell'API è effettivamente sceso da 99,66% to 99,46%Potresti fornire ulteriori dettagli o il testo che desideri tradurre? 0,2% "drop" potrebbe non sembrare molto, ma si traduce in un incredibile Aumento del 60% del tempo totale di inattività dell'API anno su anno. Questo si traduce in quasi nove ore in più di interruzioni del servizio all'anno. Se desideri approfondire i dati da solo, puoi trovare il analisi completa dell'affidabilità dell'API di Uptrends.
Il grafico qui sotto mette davvero in prospettiva questo cambiamento anno dopo anno, evidenziando quanto sia diventato difficile mantenere un'alta disponibilità.

Questa rappresentazione mette in evidenza come un apparente calo frazionale nei parametri di performance possa trasformarsi in un notevole tempo di inattività nel mondo reale.
"Ogni millisecondo è importante. In un mondo in cui i servizi sono strettamente interconnessi, le prestazioni della tua API rappresentano le prestazioni della tua azienda. Un'API lenta diventa un collo di bottiglia che frena la crescita, mina la fiducia dei clienti e offre un vantaggio competitivo ai tuoi rivali."
In definitiva, l'obiettivo non è semplicemente rendere un'API più veloce per il gusto della velocità. Si tratta di costruire un servizio che sia resiliente, affidabile e scalabile, in grado di supportare i tuoi obiettivi aziendali. Questo richiede una mentalità proattiva che si concentra su:
- Esperienza Utente: Assicurati che qualsiasi app o servizio che utilizza la tua API rimanga veloce e reattivo.
- Stabilità Operativa: Evitare che un singolo endpoint lento provochi una reazione a catena di errori nel tuo sistema.
- Reputazione Aziendale: Mantenere la fiducia sia degli utenti che dei partner che dipendono dai tuoi servizi.
Essere proattivi nel migliorare le prestazioni dell'API non è solo un compito tecnico: è un investimento fondamentale per la salute e il successo a lungo termine di tutta la tua operazione digitale.
Strategie Fondamentali per Guadagni di Prestazioni Immediati
Prima di iniziare a smantellare la tua architettura o a ristrutturare completamente il tuo stack tecnologico, ci sono alcuni aggiustamenti fondamentali che possono portare a guadagni di prestazioni significativi. Consiglio sempre ai programmatori di partire da qui. Queste sono strategie ad alto impatto e basso sforzo che fungono da prima linea di difesa contro la latenza e un'esperienza utente lenta.
Pensala in questo modo: se la tua API è un servizio di consegna, queste strategie sono come ottimizzare i tuoi percorsi e ridurre le dimensioni dei pacchi. Alla fine, consegni di più, più velocemente, senza dover avere un camion più grande.
Padroneggia l'Arte della Cache
Una delle cose più potenti che puoi fare per migliorare la velocità è semplicemente smettere di svolgere lavori superflui. È qui che entra in gioco la memorizzazione nella cache. La memorizzazione nella cache è semplicemente la pratica di conservare i risultati di operazioni costose—come una grande query su un database o un calcolo complesso—e riutilizzare quel risultato per richieste identiche che arrivano in seguito. Invece di interrogare i tuoi server backend ogni volta per gli stessi dati, fornisci una copia salvata da una cache molto più veloce.
Ho visto che questo funziona alla grande per gli endpoint che servono dati statici o che cambiano raramente, come i profili utente, i cataloghi di prodotti o le impostazioni di configurazione.
Implementando una cache intelligente, non stai solo velocizzando le risposte; stai riducendo in modo significativo il carico su tutta la tua infrastruttura. Questo libera risorse preziose per gestire le richieste uniche e dinamiche che richiedono davvero potenza di elaborazione.
Una cache efficace dipende dalla scelta dello strumento giusto per il lavoro. Diverse situazioni richiedono strategie diverse, ognuna con i propri compromessi.
Confronto tra Strategie di Caching e Casi d'Uso
Ecco una rapida panoramica delle tecniche di caching comuni che ho utilizzato, dove funzionano meglio e a cosa prestare attenzione.
| Strategia di Caching | Ideale per | Pros | Cons |
|---|---|---|---|
| Cache in memoria | Dati piccoli e frequentemente accessibili su un singolo server (ad es., impostazioni dell'app). | Tempi di accesso estremamente rapidi; facile da implementare. | Limitato dalla RAM del server; i dati vengono persi al riavvio; non condivisi tra le istanze. |
| Cache Distribuito | Applicazioni ad alto traffico con più server che necessitano di uno stato di cache condiviso. | Scalabile; resistente ai guasti di un singolo nodo; dati coerenti tra i servizi. | Più complesso da configurare e mantenere (ad esempio, Redis, Memcached). |
| Caching CDN | Risorse statiche e risposte API accessibili pubblicamente (ad es., immagini, dati di prodotto pubblici). | Riduce la latenza per gli utenti globali; allevia il traffico dai server di origine. | Può essere costoso; l'invalidazione della cache può essere complicata; non è adatto per dati riservati. |
| Caching HTTP | Caching lato client per evitare richieste ripetute per la stessa risorsa. | Riduce completamente il traffico di rete; consente al cliente di essere più efficiente. | Dipende dall'implementazione del cliente; minore controllo sullo stato della cache. |
Scegliere la strategia giusta, o anche una combinazione di esse, può fare una differenza enorme nella reattività della tua API per gli utenti.
Ottimizza i tuoi Payloads
Un'altra grande fonte di latenza è la dimensione dei dati che stai inviando attraverso la rete. È un dato di fatto: payload grandi e gonfi richiedono più tempo per essere trasmessi e più tempo per essere elaborati dal client. Ogni singolo campo non necessario che invii contribuisce a quel ritardo.
Ecco i miei due metodi preferiti per ridurre i payload:
- Compressione dei Dati: È una scelta ovvia. Utilizza algoritmi di compressione standard come Gzip or BrotliQuesti strumenti possono ridurre notevolmente la dimensione delle risposte JSON o XML, a volte fino a 70-80%La maggior parte dei server web e dei client supporta questa funzionalità già da subito, con solo alcune modifiche di configurazione.
- Filtraggio dei Campi: Non inviare tutto il pacchetto quando il cliente ha bisogno solo di un cucchiaio di zucchero. Offri ai clienti la possibilità di specificare solo i campi di cui hanno bisogno. Questo è un concetto fondamentale in GraphQL, ma puoi facilmente implementare una versione base in un'API REST con un semplice
fieldsparametro di query.
Guarda che tipo di impatto possono avere queste ottimizzazioni sui tempi di risposta e sul throughput.
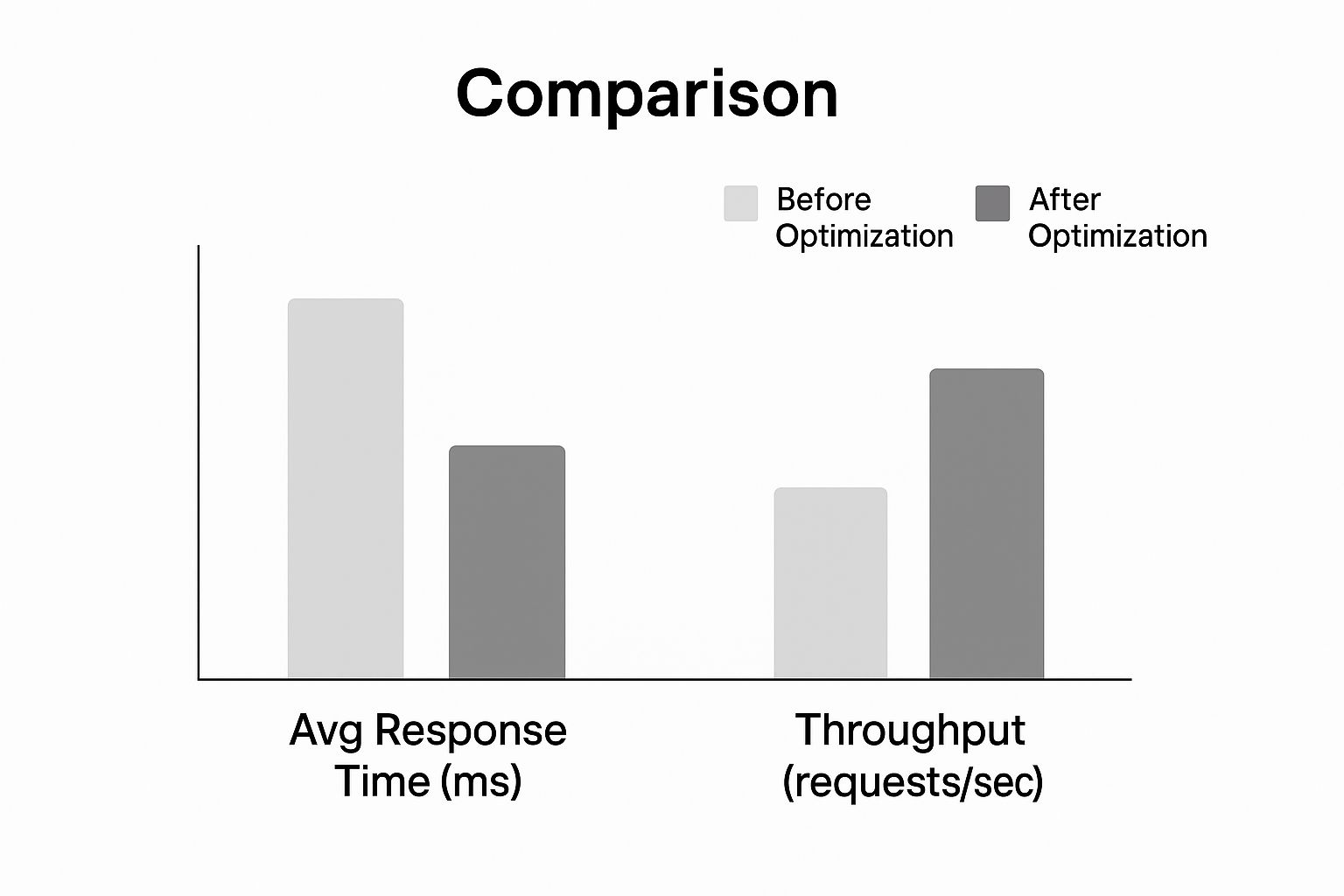
Come mostra il grafico, l'applicazione di queste strategie fondamentali porta a una drastica riduzione dei tempi di risposta, consentendo all'API di gestire un volume di richieste molto più elevato. Questi due cambiamenti possono rendere la tua API notevolmente più reattiva.
Per un approfondimento sui concetti correlati, dai un'occhiata alla nostra guida su Migliori pratiche per l'integrazione delle APIDominando queste basi, stabilirai un solido punto di riferimento per le prestazioni prima ancora di pensare di affrontare sfide architettoniche più complesse.
Controllo del Traffico con Limiti di Velocità Intelligenti e Throttling
Prima o poi, un afflusso incontrollato di richieste metterà in ginocchio anche l'API più robusta. L'ho visto accadere. Che si tratti di uno script fuori controllo, di un momento virale improvviso o di un attore malevolo, il traffico incontrollato rappresenta una minaccia diretta per la disponibilità e le prestazioni della tua API. È proprio per questo che implementare soluzioni intelligenti è fondamentale. limitazione della frequenza and throttling non è solo una buona idea: è imprescindibile.
Considera questi controlli come agenti di polizia per la tua API. Stabiliscano regole chiare su quante richieste un utente può effettuare in un determinato intervallo di tempo, proteggendo i tuoi servizi backend da un sovraccarico. Questo garantisce un utilizzo equo per tutti e impedisce che un "vicino rumoroso" rovini l'esperienza per tutti gli altri utenti.

Una strategia di limitazione del tasso ben progettata è la tua prima linea di difesa per migliora le prestazioni dell'API sotto pressione. Non si tratta solo di rifiutare ciecamente le richieste; è fondamentale gestire con saggezza la capacità per mantenere la stabilità. Senza di essa, rischi di innescare una serie di guasti che potrebbero mandare offline l'intero sistema.
Scegliere il Giusto Algoritmo di Limitazione
Non tutte le strategie di limitazione del traffico sono uguali. L'algoritmo che scegli influisce direttamente sulla flessibilità e sulla giustizia con cui puoi gestire il traffico. Analizziamo le strategie più comuni che ho implementato e i compromessi pratici di ciascuna.
- Finestra Fissa: Il metodo più semplice in circolazione. Conta semplicemente le richieste di un utente all'interno di una finestra temporale fissa, come 100 richieste al minuto. Sebbene sia facile da configurare, può causare picchi di traffico ai margini della finestra. Un utente potrebbe effettuare 100 richieste alle 11:59:59 e un'altra 100 alle 12:00:00, raddoppiando di fatto il loro limite.
- Finestra Scorrevole: Questo approccio risolve il problema dei picchi di richieste monitorando le richieste su una finestra temporale mobile. Ti offre un limite di velocità molto più preciso, ma ha un costo: richiede maggiore capacità di archiviazione dei dati e potenza di calcolo per essere mantenuto.
- Token Bucket: Questo è il mio metodo preferito per la sua straordinaria flessibilità. Ogni utente riceve un "cestino" di token che si ricarica a un ritmo costante. Ogni richiesta API consuma un token. Questa configurazione consente picchi brevi di traffico (finché hai token a disposizione) ma garantisce una media costante nel tempo, il che è fantastico per l'esperienza dell'utente.
L'algoritmo del bucket di token, ad esempio, è perfetto per un servizio come LATE. Un utente potrebbe aver bisogno di programmare un'improvvisa serie di post sui social media tutti in una volta, per poi avere periodi più tranquilli. Questo algoritmo si adatta a questo modello di utilizzo legittimo senza compromettere la salute del sistema.
Il rate limiting non è solo una misura difensiva; è uno strumento per modellare il comportamento degli utenti e garantire un accesso equo alle risorse della tua API. Una politica ben progettata migliora l'equità e la prevedibilità per tutti i consumatori.
Regole personalizzate per scenari diversi
Un limite di utilizzo universale non funziona nel mondo reale. Per proteggere davvero la tua API mentre servi gli utenti in modo efficace, devi essere più specifico e personalizzare le tue regole. Un ottimo punto di partenza è implementare limiti diversi in base ai livelli di abbonamento degli utenti.
| Livello Utente | Esempio di Limite di Richiesta | Caso d'uso |
|---|---|---|
| Piano Gratuito | 100 richieste/ora | Per utenti in prova e progetti personali a basso volume. |
| Piano Base | 1.000 richieste/ora | Per piccole imprese e applicazioni in crescita. |
| Piano Enterprise | 10.000 richieste/ora | For high-volume customers with mission-critical needs. |
Questo approccio a livelli non solo protegge la tua infrastruttura, ma crea anche un percorso di aggiornamento chiaro per gli utenti man mano che le loro esigenze crescono. Puoi anche essere più specifico applicando limiti più rigorosi agli endpoint che richiedono molte risorse (come una ricerca complessa nel database), mentre puoi essere più generoso con quelli leggeri (come un semplice controllo dello stato).
Per un'analisi ancora più approfondita di queste strategie, dai un'occhiata alla nostra guida su Migliori pratiche per il limite di frequenza delle APIImplementando questi controlli intelligenti, puoi garantire che la tua API rimanga veloce, equa e accessibile a tutti.
Progettare per la Scalabilità e un Pubblico Globale
Quando inizi, una configurazione su un singolo server sembra semplice e fa il suo dovere. È perfetta per una piccola base utenti locale. Ma cosa succede quando la tua app inizia a decollare a livello globale? Quella architettura un tempo affidabile si trasforma rapidamente nel tuo più grande incubo in termini di prestazioni.
To migliora le prestazioni dell'API Per un pubblico internazionale in crescita, devi smettere di pensare a un singolo server e iniziare a considerare un sistema distribuito e globale.
Il nemico numero uno qui è latencyOgni richiesta da un utente a Tokyo al tuo server in Virginia deve percorrere migliaia di chilometri, aggiungendo centinaia di millisecondi di latenza prima che il tuo codice inizi a essere eseguito. Questo è esattamente il motivo per cui un Rete di Distribuzione dei Contenuti (CDN) non è solo un'opzione gradita; è fondamentale. Un CDN memorizza nella cache le risposte della tua API in posizioni "edge" in tutto il mondo, il che significa che gli utenti vengono serviti da un server geograficamente vicino, riducendo drasticamente il tempo di percorrenza della rete.
Abbraccia la Scalabilità Orizzontale
Non si tratta solo di distanza; è una questione di volume. Man mano che sempre più utenti accedono alla tua API, hai bisogno di una strategia per gestire il carico. È qui che scalabilità orizzontale entra in gioco. Invece di potenziare un singolo server (scalabilità verticale), aggiungi più macchine alla tua flotta, distribuendo il lavoro tra di esse.
La magia avviene con un bilanciatore di caricoQuesto componente si trova davanti ai tuoi server, fungendo da vigile del traffico, indirizzando in modo intelligente le richieste in arrivo verso la macchina meno occupata. Questo evita che un singolo server venga sovraccaricato e costruisce un’incredibile resilienza. Se un server fallisce? Nessun problema. Il bilanciatore di carico reindirizza semplicemente il traffico verso quelli funzionanti, mantenendo il tuo API online.
Questa strategia è perfetta per un architettura a microserviziSuddividendo la tua grande applicazione in piccoli servizi indipendenti, puoi scalare solo le parti che ne hanno bisogno. Ad esempio, se il tuo servizio di accesso degli utenti è sotto pressione durante le ore di punta, puoi avviare più istanze di quel servizio senza dover toccare nient'altro.
Progettare per la scalabilità non significa solo gestire un maggior traffico; si tratta di costruire un sistema resiliente e adattabile. Distribuendo sia i tuoi dati che le tue risorse di calcolo, crei un'API che è intrinsecamente più veloce e affidabile per ogni utente, indipendentemente da dove si trovi.
Costruire una presenza globale resiliente
Passare a un'architettura distribuita significa quasi sempre abbandonare i server on-premise per un ambiente cloud flessibile che può crescere insieme a te. Progettare per un pubblico globale implica impostare correttamente la tua infrastruttura fin dall'inizio. Se sei nuovo in questa transizione, approfondire un guida esperta per migrare i server nel cloud può essere di grande aiuto.
Ecco i punti chiave per costruire una presenza globale resiliente:
- Endpoint regionali: Non limitarti a una sola distribuzione. Attiva istanze della tua API in diverse regioni geografiche come Nord America, Europa e Asia. In questo modo, puoi indirizzare gli utenti verso quella più vicina a loro, riducendo notevolmente la latenza.
- Replica del database: Un'unica base di dati può diventare un enorme collo di bottiglia. Utilizza repliche di lettura in diverse regioni per fornire dati localmente. Questo accelera le operazioni di lettura per gli utenti lontani dal tuo database principale.
- Controlli di Salute: Configura il tuo bilanciatore di carico per controllare costantemente lo stato dei tuoi server. Se un'istanza diventa non rispondente, il bilanciatore di carico la rimuoverà automaticamente dal ciclo, evitando che gli utenti vedano errori.
Quando combini queste strategie, crei un sistema potente e multi-livello. Il CDN gestisce il primo punto di contatto, il bilanciatore di carico distribuisce il lavoro e i deployment regionali garantiscono che l'elaborazione avvenga il più vicino possibile all'utente. Questo è il modello per qualsiasi API che mira a servire un pubblico globale in crescita senza intoppi.
L'impatto dell'automazione e dell'IA sulle prestazioni delle API
Non è un segreto che l'intelligenza artificiale abbia completamente rivoluzionato le nostre infrastrutture digitali. Ogni chatbot, ogni strumento di analisi dei dati, ogni nuova funzionalità alimentata dall'IA si basa su una rete di API per svolgere il proprio lavoro. Questo ha generato un'enorme quantità di traffico che i sistemi più vecchi, gestiti manualmente, non sono semplicemente in grado di gestire.
Non stiamo parlando solo di un piccolo aumento nelle richieste. Si tratta di un vero e proprio nuovo paradigma. Questa esplosione guidata dall'IA ha generato un impatto straordinario. 73% un aumento delle chiamate API legate all'IA in tutto il mondo, mettendo a dura prova le infrastrutture per tenere il passo. È per questo che le piattaforme di generazione automatica di API, in grado di ridurre i tempi di sviluppo di circa 85%, stanno diventando sempre più fondamentali. Puoi leggere di più su come Il boom delle API per l'IA rafforza questa necessità di automazione su blog.dreamfactory.com.

Superare lo sviluppo manuale
In questa nuova realtà, il vecchio modo di fare le cose—costruire, distribuire e gestire manualmente ogni API—è un vicolo cieco. I processi manuali sono lenti, soggetti a errori umani e Cercare di gestire questa complessità a mano crea enormi colli di bottiglia che ostacolano le prestazioni e l'innovazione.
L'automazione non è più un "optional"; è un imperativo strategico. Automatizzando l'intero ciclo di vita dell'API—dalla creazione e test fino al deployment e monitoraggio—crei servizi più resilienti, sicuri e scalabili fin dall'inizio.
L'obiettivo non è solo quello di costruire API più velocemente. Si tratta di integrare prestazioni e sicurezza direttamente nel processo di sviluppo, garantendo che la tua infrastruttura possa gestire le intense richieste dell'era dell'IA senza necessità di interventi manuali continui.
L'automazione della gestione delle API ti consente di concentrarti su ciò che conta davvero: offrire valore. Quando non sei bloccato nei dettagli della manutenzione ripetitiva, puoi innovare. Un ottimo esempio pratico è semplificare le attività di outreach con un API per l'automazione del marketing.
Il Vantaggio Strategico della Generazione Automatica
L'ascesa dell'IA ci ha fornito strumenti che semplificano anche lo sviluppo del backend. Se approfondisci, vedrai come soluzioni AI backend senza codice stanno completamente ridefinendo il panorama. Queste piattaforme portano l'automazione a un livello superiore, generando API pronte per la produzione e di alta qualità con pochissimo codice manuale.
Questo approccio ti offre alcuni vantaggi principali per migliorare le prestazioni dell'API:
- Distribuzione Accelerata: I team possono lanciare nuove API in una frazione del tempo necessario con i metodi tradizionali. Questo ti consente di reagire rapidamente ai cambiamenti del mercato.
- Pratiche migliori integrate: Queste piattaforme integrano per impostazione predefinita elementi essenziali come la sicurezza OAuth, il limitamento della frequenza e la memorizzazione nella cache. Questo chiude le comuni vulnerabilità di sicurezza prima ancora che possano diventare un problema.
- Scalabilità Coerente: Le API generate in questo modo sono solitamente costruite su architetture scalabili fin dall'inizio, pronte a gestire il traffico imprevedibile che i servizi di intelligenza artificiale possono generare.
In definitiva, non puoi permetterti di ignorare l'automazione e l'intelligenza artificiale nella tua strategia API. È il modo più pratico per costruire e mantenere l'infrastruttura ad alte prestazioni, sicura e scalabile di cui hai bisogno per competere oggi.
Domande Frequenti sulle Prestazioni dell'API
Quando inizi a esaminare le prestazioni delle API, ti accorgerai che le stesse domande emergono ripetutamente. Ho visto queste questioni mettere in difficoltà anche i team più esperti. Affrontarle nel modo giusto fa la differenza tra un'API che funziona e una che è davvero veloce e resiliente.
Affrontiamo alcuni dei grandi temi.
First up: caching. Everyone knows they should cache, ma la vera domanda è howNon si tratta semplicemente di attivare un interruttore; si tratta di adattare la strategia di caching ai tuoi dati specifici. Se stai fornendo dati pubblici e statici a un'utenza globale, un... CDN è una scelta ovvia. Ma che dire dei dati specifici di una sessione utente che devono essere accessibili su più server? È qui che entra in gioco una cache distribuita come Redis brilla. La vera competenza risiede nella comprensione del ciclo di vita dei tuoi dati e di come vengono utilizzati.
Poi c'è la questione delicata del rate limiting. Come proteggere il tuo servizio dagli abusi senza escludere gli utenti legittimi? L'errore da principianti è applicare un limite universale. Non farlo.
Un limite di utilizzo ben progettato non è solo un guardiano; è una guida che incoraggia un uso equo proteggendo al contempo la tua infrastruttura. Dovrebbe sembrare una barriera di protezione, non un muro di mattoni.
Un approccio più intelligente è sfumato. Inizia impostando limiti diversi per i vari livelli di utenti: il tuo piano gratuito non dovrebbe avere lo stesso accesso di un cliente enterprise ad alto pagamento. Rendi le cose ancora più dettagliate applicando limiti più severi ai tuoi endpoint più costosi. Una chiamata complessa per la generazione di report dovrebbe avere una soglia molto più bassa rispetto a una semplice. OTTENERE /stato Questo protegge le tue risorse più impegnative senza penalizzare le attività normali.
Quando è il momento di rifattorizzare per scalare?
Questa potrebbe essere la domanda più importante di tutte. Quando smettere di fare patch e iniziare a ricostruire? La risposta si trova quasi sempre nei tuoi dati di monitoraggio. Se i tuoi tempi di risposta stanno lentamente ma inesorabilmente aumentando, anche dopo aver ottimizzato le query e aggiunto cache, è un segnale. Se un servizio specifico è costantemente al 100% di CPU durante le ore di punta, questo è un altro indicatore.
Probabilmente hai superato la tua attuale architettura quando noti questi segnali inequivocabili:
- Latente Persistente: Your and Le metriche di latenza sono sorprendentemente elevate, anche per richieste semplici e quotidiane.
- Punti Dolenti Geografici: Inizi a ricevere lamentele costanti riguardo a prestazioni lente da parte degli utenti in regioni specifiche, lontane dai tuoi server.
- Colli di bottiglia nella scalabilità: Un'unica base di dati o servizio raggiunge costantemente il limite delle sue risorse ogni volta che ci sono picchi di traffico.
Riconoscere questi schemi è il tuo segnale. Significa che le piccole modifiche non sono più sufficienti e che è il momento di investire in un'architettura più scalabile. Questo potrebbe comportare il passaggio a una scalabilità orizzontale con bilanciatori di carico, il deployment della tua API in più regioni, o infine la suddivisione di quel monolite in microservizi. È un'impresa significativa, ma è l'unico modo per garantire che la tua API possa gestire una crescita a lungo termine e rimanere affidabile.
Pronto a smettere di destreggiarti tra più API dei social media? LATE offre un'unica API unificata per pianificare contenuti su sette piattaforme principali con 99,97% tempo di attività e sottoscrizione50 ms risposte. Inizia a costruire gratuitamente oggi stesso!.