Lorsque vous travaillez à améliorer les performances de votre API, la stratégie est assez simple : réduisez les latencyréduisez la taille de vos charges utiles et optimisez votre mise en cache. Maîtrisez ces trois fondamentaux, et vous disposerez d'une API non seulement rapide et efficace, mais aussi capable d'offrir une expérience fiable qui satisfait les utilisateurs et propulse votre entreprise vers l'avant.
Pourquoi la performance des API est-elle plus cruciale que jamais ?
Dans le monde actuel, les applications sont toutes interconnectées, et les API sont les fils qui maintiennent le tout ensemble. Une API lente ou instable n'est pas simplement une petite gêne qui provoque un léger retard. C'est un coup direct à la fidélisation des utilisateurs, à l'efficacité opérationnelle et aux résultats de votre entreprise. Lorsqu'une API rencontre des problèmes, cela peut créer un effet domino massif, dégradant chaque service qui en dépend.
Pensez à votre application de banque mobile. Si l'appel API pour récupérer le solde de votre compte prend du temps, votre confiance envers cette banque commence à s'effriter. Imaginez un site de e-commerce où l'API de la passerelle de paiement est lente : ce délai conduit directement aux paniers abandonnés et aux ventes perdues. C'est pourquoi l'optimisation des performances des API est passée d'une pratique technique « agréable à avoir » à une stratégie commerciale essentielle. Les gens s'attendent à ce que tout soit instantané, et leur patience face aux retards a pratiquement disparu.
Le véritable coût de l'interruption de service
Même une légère baisse de votre pourcentage de disponibilité peut avoir des conséquences étonnamment importantes. Nous avons récemment observé des données plutôt inquiétantes : entre T1 2024 and T1 2025, la disponibilité moyenne de l'API a en réalité chuté à 99,66 % to 99,46 %Pourriez-vous fournir plus de détails ou le texte que vous souhaitez traduire ? 0,2 % "drop" peut sembler insignifiant, mais cela se traduit par un chiffre impressionnant. augmentation de 60 % du temps d'arrêt total de l'API données vous-même, vous pouvez consulter le analyse complète de la fiabilité de l'API d'Uptrends.
Le graphique ci-dessous illustre clairement l'évolution d'une année sur l'autre, mettant en lumière à quel point il est devenu difficile de garantir une haute disponibilité.

Cette illustration souligne que même une légère baisse des indicateurs de performance peut entraîner un temps d'arrêt considérable dans la réalité.
« Chaque milliseconde compte. Dans un monde où les services sont étroitement liés, la performance de votre API est celle de votre entreprise. Une API lente devient un goulet d'étranglement qui freine la croissance, érode la confiance des clients et offre un avantage concurrentiel à vos rivaux. »
En fin de compte, l'objectif ici n'est pas simplement d'accélérer une API pour le plaisir de la vitesse. Il s'agit de créer un service qui soit résilient, fiable et suffisamment évolutif pour soutenir vos objectifs commerciaux. Cela nécessite un état d'esprit proactif axé sur :
- Expérience Utilisateur : Assurez-vous que toute application ou service utilisant votre API reste rapide et réactif.
- Stabilité opérationnelle : Empêcher qu'un seul point de terminaison lent ne provoque une réaction en chaîne de pannes dans votre système.
- Réputation d'entreprise : Maintenir la confiance de vos utilisateurs ainsi que de vos partenaires qui dépendent de vos services.
Être proactif dans l'amélioration des performances de l'API n'est pas seulement une tâche technique, c'est un investissement essentiel pour la santé et le succès à long terme de l'ensemble de votre opération numérique.
Stratégies fondamentales pour des gains de performance immédiats
Avant de vous lancer dans la refonte de votre architecture ou de revoir complètement votre stack technologique, il existe quelques ajustements fondamentaux qui peuvent offrir des gains de performance significatifs. Je conseille toujours aux développeurs de commencer par là. Ce sont des stratégies à fort impact et faible effort qui constituent votre première ligne de défense contre la latence et une expérience utilisateur lente.
Pensez-y de cette manière : si votre API est un service de livraison, ces stratégies sont comme l'optimisation de vos itinéraires et la réduction de la taille de vos colis. Vous finissez par livrer plus, plus rapidement, sans avoir besoin d'un camion plus grand.
Maîtrisez l'art du caching
L'une des choses les plus efficaces pour améliorer la vitesse est tout simplement d'arrêter de faire du travail inutile. C'est là qu'intervient la mise en cache. La mise en cache consiste à stocker les résultats d'opérations coûteuses—comme une requête complexe sur une grande base de données ou un calcul élaboré—et à réutiliser ce résultat pour des demandes identiques qui arrivent par la suite. Au lieu de solliciter vos serveurs backend à chaque fois pour les mêmes données, vous servez une copie enregistrée provenant d'un cache beaucoup plus rapide.
J'ai constaté que cela fonctionne à merveille pour les points de terminaison qui servent des données statiques ou peu souvent modifiées, comme les profils utilisateurs, les catalogues de produits ou les paramètres de configuration.
En mettant en place un cache intelligent, vous ne vous contentez pas d'accélérer les réponses ; vous réduisez fondamentalement la charge sur l'ensemble de votre infrastructure. Cela libère des ressources précieuses pour gérer les demandes uniques et dynamiques qui nécessitent réellement de la puissance de traitement.
Un bon système de mise en cache repose sur le choix de l'outil adapté à chaque situation. Selon les contextes, il existe différentes stratégies, chacune présentant ses propres avantages et inconvénients.
Comparaison des stratégies de mise en cache et des cas d'utilisation
Voici un aperçu des techniques de mise en cache courantes que j'ai utilisées, leurs points forts et les éléments à surveiller.
| Stratégie de mise en cache | Idéal pour | Pros | Cons |
|---|---|---|---|
| Cache en mémoire | Données petites et fréquemment consultées sur un seul serveur (par exemple, paramètres de l'application). | Des temps d'accès extrêmement rapides ; facile à mettre en œuvre. | Limité par la RAM du serveur ; les données sont perdues au redémarrage ; non partagées entre les instances. |
| Cache Distribué | Applications à fort trafic avec plusieurs serveurs nécessitant un état de cache partagé. | Scalable ; résilient face aux pannes d'un seul nœud ; données cohérentes entre les services. | Plus complexe à configurer et à maintenir (par exemple, Redis, Memcached). |
| Mise en cache CDN | Actifs statiques et réponses API accessibles au public (par exemple, images, données produit publiques). | Réduit la latence pour les utilisateurs du monde entier ; décharge le trafic des serveurs d'origine. | Peut être coûteux ; l'invalidation du cache peut être délicate ; pas adapté aux données privées. |
| Mise en cache HTTP | Mise en cache côté client pour éviter les requêtes répétées pour la même ressource. | Réduit complètement le trafic réseau ; permet au client d'être plus efficace. | Dépend de l'implémentation du client ; moins de contrôle sur l'état du cache. |
Choisir la bonne stratégie, ou même une combinaison de plusieurs, peut faire toute la différence en termes de réactivité de votre API pour vos utilisateurs.
Optimisez vos charges utiles
Une autre source majeure de latence est la taille des données que vous envoyez sur le réseau. C'est un fait simple : des charges utiles volumineuses et encombrantes mettent plus de temps à être transmises et à être analysées par le client. Chaque champ superflu que vous envoyez contribue à ce délai.
Voici mes deux méthodes incontournables pour réduire les charges utiles :
- Compression de données : C'est une évidence. Utilisez des algorithmes de compression standard tels que Gzip or BrotliCes outils peuvent réduire considérablement la taille des réponses JSON ou XML, parfois jusqu'à 70-80 %La plupart des serveurs web et des clients prennent en charge cela dès le départ avec seulement quelques modifications de configuration.
- Filtrage des champs : Ne leur envoyez pas tout un arsenal quand le client a juste besoin d'une tasse de sucre. Offrez aux clients la possibilité de spécifier uniquement les champs dont ils ont besoin. C'est un concept fondamental dans GraphQL, mais vous pouvez facilement mettre en œuvre une version basique dans une API REST avec un simple
fieldsparamètre de requête.
Regardez l'impact que ces optimisations peuvent avoir sur le temps de réponse et le débit.
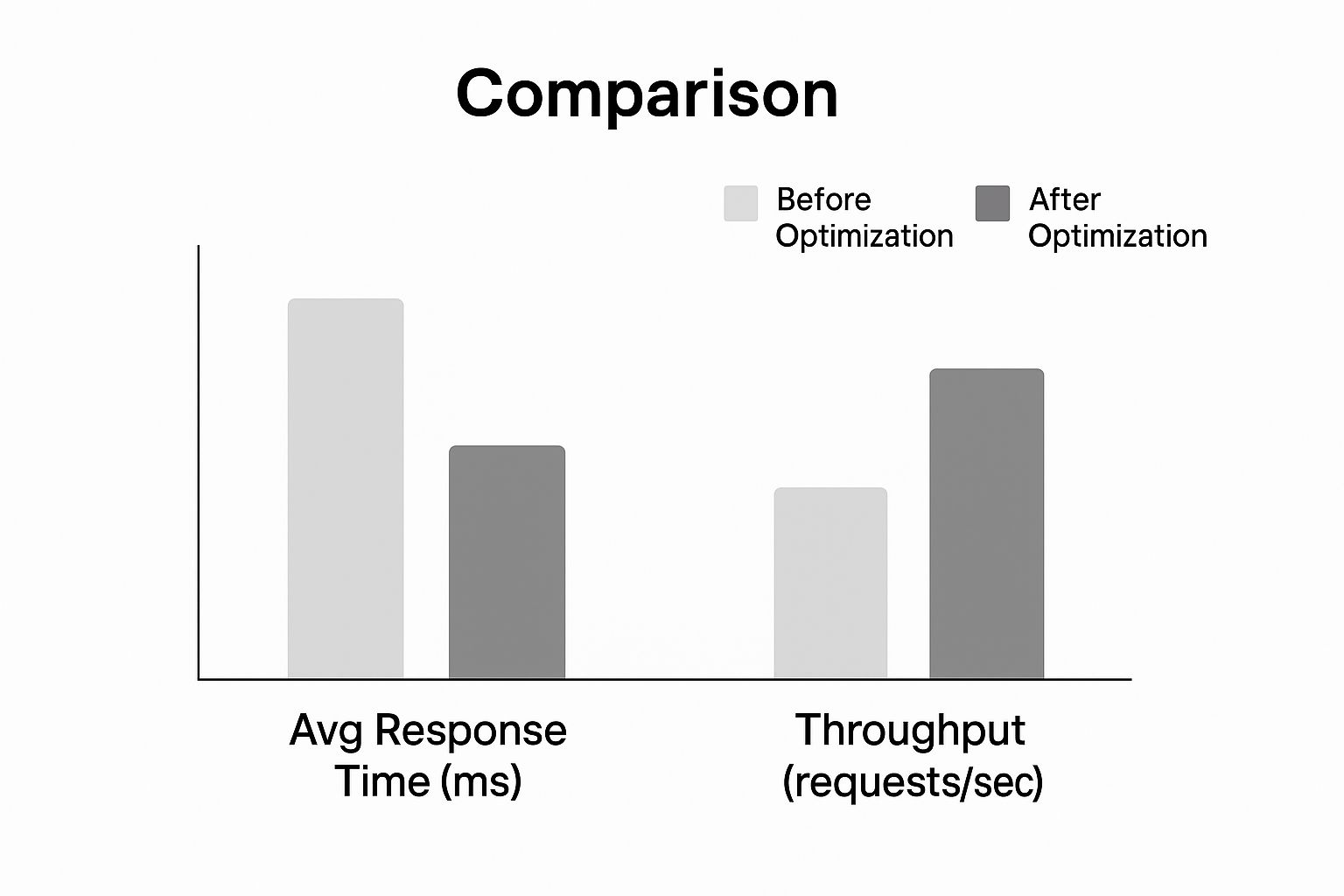
Comme le montre le graphique, l'application de ces stratégies fondamentales entraîne une réduction spectaculaire des temps de réponse tout en permettant à l'API de gérer un volume de requêtes beaucoup plus élevé. Ces deux changements à eux seuls peuvent rendre votre API nettement plus réactive.
Pour une exploration plus approfondie des concepts connexes, consultez notre guide sur Meilleures pratiques pour l'intégration d'APIEn maîtrisant ces fondamentaux, vous établirez une base de performance solide avant même de penser à aborder des défis architecturaux plus complexes.
Contrôlez le trafic grâce à un taux de limitation et un throttling intelligents.
Tôt ou tard, un afflux incontrôlé de requêtes mettra à mal même l'API la plus robuste. J'ai déjà vu cela se produire. Que ce soit à cause d'un script hors de contrôle, d'un moment viral inattendu ou d'un acteur malveillant, un trafic non maîtrisé constitue une menace directe pour la disponibilité et la performance de votre API. C'est précisément pour cette raison qu'il est essentiel de mettre en place des solutions intelligentes. limitation de taux and throttling ce n'est pas seulement une bonne idée, c'est incontournable.
Considérez ces contrôles comme des agents de circulation pour votre API. Ils appliquent des règles claires sur le nombre de requêtes qu'un utilisateur peut effectuer dans un délai donné, protégeant ainsi vos services backend d'une surcharge. Cela garantit une utilisation équitable pour tous et empêche un « voisin bruyant » de gâcher l'expérience de tous vos autres utilisateurs.

Une stratégie de limitation de taux bien conçue est votre première ligne de défense pour améliorer les performances de l'API sous pression. Il ne s'agit pas simplement de rejeter aveuglément des demandes ; il s'agit de gérer habilement la capacité pour maintenir la stabilité. Sans cela, vous risquez une cascade de défaillances qui pourrait mettre hors ligne l'ensemble de votre système.
Choisir le bon algorithme de limitation
Toutes les stratégies de limitation de débit ne se valent pas. L'algorithme que vous choisissez influence directement la flexibilité et l'équité avec lesquelles vous pouvez gérer le trafic. Analysons les approches les plus courantes que j'ai mises en œuvre ainsi que les compromis réels de chacune.
- Fenêtre fixe : La méthode la plus simple qui existe. Elle se contente de compter les requêtes d'un utilisateur sur une période de temps fixe, comme 100 demandes par minute. Bien qu'il soit facile à configurer, cela peut provoquer des pics de trafic à la limite de la fenêtre. Un utilisateur pourrait faire 100 demandes à 11:59:59 et une autre 100 à 12h00, doublant ainsi leur limite.
- Fenêtre glissante : Cette approche atténue le problème de surcharge en suivant les demandes sur une période de temps glissante. Elle vous offre une limite de taux beaucoup plus précise, mais cela a un coût : cela nécessite plus de stockage de données et de puissance de calcul pour être maintenu.
- Seau de jetons : C'est ma méthode de prédilection en raison de sa flexibilité. Chaque utilisateur dispose d'un « seau » de jetons qui se recharge à un rythme régulier. Chaque requête API consomme un jeton. Ce système permet des pics de trafic courts (tant que vous avez des jetons) tout en garantissant un taux moyen constant dans le temps, ce qui est fantastique pour l'expérience utilisateur.
L'algorithme du seau à jetons, par exemple, est idéal pour un service comme LATE. Un utilisateur peut avoir besoin de programmer une série de publications sur les réseaux sociaux en une seule fois, puis connaître des périodes plus calmes. Cet algorithme s'adapte à ce schéma d'utilisation légitime sans compromettre la santé du système.
La limitation de taux n'est pas seulement une mesure défensive ; c'est un outil pour influencer le comportement des utilisateurs et garantir un accès équitable à vos ressources API. Une politique bien pensée améliore l'équité et la prévisibilité pour tous les consommateurs.
Règles de personnalisation pour différents scénarios
Une limite de taux unique ne fonctionne tout simplement pas dans le monde réel. Pour protéger réellement votre API tout en servant efficacement vos utilisateurs, vous devez adopter une approche plus granulaire et adapter vos règles. Un excellent point de départ consiste à mettre en place des limites différentes en fonction des niveaux d'abonnement des utilisateurs.
| Niveau d'utilisateur | Exemple de Limite de Taux | Cas d'utilisation |
|---|---|---|
| Niveau gratuit | 100 demandes/heure | Pour les utilisateurs en essai et les projets personnels de faible volume. |
| Niveau de base | 1 000 demandes/heure | Pour les petites entreprises et les applications en pleine croissance. |
| Niveau Entreprise | 10 000 demandes/heure | For high-volume customers with mission-critical needs. |
Cette approche par niveaux protège non seulement votre infrastructure, mais crée également un chemin d'évolution clair pour les utilisateurs au fur et à mesure que leurs besoins se développent. Vous pouvez également être plus précis en appliquant des limites plus strictes aux points de terminaison gourmands en ressources (comme une recherche complexe dans une base de données) tout en étant plus généreux avec ceux qui sont légers (comme une simple vérification de statut).
Pour une exploration encore plus approfondie de ces stratégies, consultez notre guide sur Meilleures pratiques pour la gestion des limites de taux d'APIEn mettant en place ces contrôles intelligents, vous pouvez garantir que votre API reste rapide, équitable et accessible à tous.
Concevoir pour l'échelle et un public mondial
Lorsque vous débutez, une configuration sur un seul serveur semble simple et fait le travail. C'est idéal pour une petite base d'utilisateurs locale. Mais que se passe-t-il lorsque votre application commence à se développer à l'échelle mondiale ? Cette architecture autrefois fiable se transforme rapidement en votre plus gros casse-tête en matière de performance.
To améliorer les performances de l'API Pour un public international en pleine expansion, il est temps de cesser de penser en termes de serveur unique et de commencer à envisager un système distribué à l'échelle mondiale.
Le principal ennemi ici est latencyChaque requête d'un utilisateur à Tokyo vers votre serveur en Virginie doit parcourir des milliers de kilomètres, ce qui ajoute des centaines de millisecondes de latence avant même que votre code ne commence à s'exécuter. C'est précisément pour cette raison qu'un Réseau de Distribution de Contenu (RDC) ce n'est pas qu'un simple atout ; c'est essentiel. Un CDN met en cache vos réponses API dans des emplacements "edge" à travers le monde, ce qui signifie que les utilisateurs sont servis par un serveur géographiquement proche, réduisant ainsi le temps de latence réseau.
Adoptez l'évolutivité horizontale
Il ne s'agit pas seulement de distance, mais aussi de volume. À mesure que de plus en plus d'utilisateurs accèdent à votre API, il est essentiel d'avoir une stratégie pour gérer cette charge. C'est ici que scalabilité horizontale au lieu de renforcer un seul serveur (scalabilité verticale), vous ajoutez davantage de machines à votre parc, répartissant ainsi la charge de travail entre elles.
La magie opère avec un équilibreur de chargeCe composant se place devant vos serveurs, agissant comme un régulateur de trafic, dirigeant intelligemment les requêtes entrantes vers la machine la moins sollicitée. Cela empêche un serveur de devenir surchargé et renforce considérablement la résilience. Si un serveur tombe en panne ? Pas de souci. Le répartiteur de charge redirige simplement le trafic vers les serveurs opérationnels, maintenant ainsi votre API en ligne.
Cette stratégie est parfaitement adaptée à un architecture de microservicesEn divisant votre grande application en petits services indépendants, vous pouvez faire évoluer uniquement les parties qui en ont besoin. Par exemple, si votre service de connexion utilisateur est fortement sollicité pendant les heures de pointe, vous pouvez déployer davantage d'instances de ce service sans toucher aux autres.
Concevoir pour l'échelle ne se limite pas à gérer un volume de trafic plus important ; il s'agit de créer un système résilient et adaptable. En répartissant à la fois vos données et vos ressources de calcul, vous développez une API qui est intrinsèquement plus rapide et plus fiable pour chaque utilisateur, peu importe où il se trouve.
Construire une empreinte mondiale résiliente
Passer à une architecture distribuée signifie presque toujours abandonner les serveurs sur site au profit d'un environnement cloud flexible qui peut évoluer avec vous. Concevoir pour un public mondial implique de bien établir votre infrastructure dès le départ. Si vous êtes novice dans cette transition, il est essentiel de plonger dans un guide expert sur la migration des serveurs vers le cloud peut être d'une grande aide.
Voici les éléments clés pour établir une empreinte mondiale résiliente :
- Points de terminaison régionaux : Ne vous limitez pas à un seul déploiement. Déployez des instances de votre API dans plusieurs régions géographiques comme l'Amérique du Nord, l'Europe et l'Asie. Cela vous permet de diriger les utilisateurs vers l'instance la plus proche, réduisant ainsi considérablement la latence.
- Réplique de Base de Données : Une seule base de données peut rapidement devenir un goulot d'étranglement. Utilisez réplicas de lecture dans différentes régions pour fournir des données localement. Cela accélère les opérations de lecture pour les utilisateurs éloignés de votre base de données principale.
- Vérifications de santé : Configurez votre répartiteur de charge pour qu'il effectue des pings réguliers sur vos serveurs afin de vérifier leur état de santé. Si une instance devient non réactive, le répartiteur de charge la retirera automatiquement de la rotation, évitant ainsi aux utilisateurs de rencontrer des erreurs.
En combinant ces stratégies, vous créez un système puissant et multi-niveaux. Le CDN gère le premier point de contact, le répartiteur de charge répartit le travail, et les déploiements régionaux garantissent que le traitement se fait aussi près que possible de l'utilisateur. C'est le modèle à suivre pour toute API qui souhaite servir un public mondial en pleine croissance sans accroc.
L'impact de l'automatisation et de l'IA sur la performance des API
Il n'est pas surprenant que l'intelligence artificielle ait complètement révolutionné notre infrastructure numérique. Chaque chatbot, chaque outil d'analyse de données, chaque nouvelle fonctionnalité alimentée par l'IA repose sur un réseau d'API pour fonctionner. Cela a engendré un flot de trafic que les systèmes plus anciens, gérés manuellement, ne sont tout simplement pas conçus pour gérer.
Nous ne parlons pas simplement d'une légère augmentation des demandes. C'est un tout nouveau paradigme. Cette explosion alimentée par l'IA a provoqué une augmentation stupéfiante. 73 % une augmentation des appels d'API liés à l'IA dans le monde entier, mettant une pression incroyable sur l'infrastructure pour suivre le rythme. C'est pourquoi les plateformes de génération d'API automatisées, qui peuvent réduire le temps de développement d'environ 85 %, deviennent de plus en plus essentiels. Vous pouvez en savoir plus sur la façon dont Le boom des API liées à l'IA renforce ce besoin d'automatisation sur blog.dreamfactory.com.

Aller au-delà du développement manuel
Dans cette nouvelle réalité, l'ancienne méthode consistant à construire, déployer et gérer manuellement chaque API est une impasse. Les processus manuels sont lents, sujets aux erreurs humaines, et ne peuvent tout simplement pas suivre le rythme imposé par l'IA. Tenter de gérer cette complexité à la main engendre d'énormes goulets d'étranglement qui freinent la performance et l'innovation.
L'automatisation n'est plus un simple atout ; c'est une nécessité stratégique. En automatisant l'ensemble du cycle de vie de l'API—de la création et des tests au déploiement et à la surveillance—vous construisez des services plus résilients, sécurisés et évolutifs dès le départ.
L'objectif n'est pas seulement de créer des API plus rapidement. Il s'agit d'intégrer la performance et la sécurité directement dans le processus de développement, garantissant que votre infrastructure puisse répondre aux exigences élevées de l'ère de l'IA sans nécessiter d'interventions manuelles constantes.
L'automatisation de la gestion des API vous permet de vous concentrer sur ce qui compte vraiment : apporter de la valeur. Lorsque vous n'êtes pas coincé dans les tâches répétitives de maintenance, vous pouvez innover. Un excellent exemple concret est l'optimisation de la prospection avec un API d'automatisation marketing.
L'Avantage Stratégique de la Génération Automatisée
L'essor de l'IA nous a également offert des outils qui simplifient le développement backend. Si vous creusez un peu, vous verrez comment solutions AI backend sans code redéfinissent complètement le paysage. Ces plateformes poussent l'automatisation encore plus loin en générant des API prêtes à l'emploi et de haute qualité avec très peu de codage manuel.
Cette approche vous offre plusieurs avantages majeurs pour améliorer les performances de l'APIPourriez-vous fournir le texte que vous souhaitez que je traduise ?
- Déploiement Accéléré : Les équipes peuvent déployer de nouvelles API en un temps record, bien plus rapidement qu'avec les méthodes traditionnelles. Cela vous permet de réagir rapidement aux évolutions du marché.
- Meilleures pratiques intégrées : Ces plateformes intègrent par défaut des éléments essentiels tels que la sécurité OAuth, la limitation de débit et le cache. Cela permet de combler les failles de sécurité courantes avant même qu'elles ne deviennent un problème.
- Scalabilité cohérente : Les API générées de cette manière sont généralement conçues dès le départ sur des architectures évolutives, prêtes à gérer le trafic imprévisible que les services d'IA peuvent leur imposer.
En fin de compte, vous ne pouvez pas vous permettre d'ignorer l'automatisation et l'IA dans votre stratégie API. C'est la manière la plus pratique de construire et de maintenir l'infrastructure performante, sécurisée et évolutive dont vous avez besoin pour rester compétitif aujourd'hui.
Questions Fréquemment Posées sur la Performance de l'API
En commençant à explorer les performances des API, vous constaterez que les mêmes questions reviennent sans cesse. J'ai vu ces interrogations déstabiliser même des équipes expérimentées. Savoir y répondre correctement fait toute la différence entre une API qui fonctionne simplement et une API qui est véritablement rapide et résiliente.
Abordons quelques-uns des grands sujets.
Tout d'abord : le cache. Tout le monde sait qu'ils should cache, mais la vraie question est howCe n'est pas simplement une question d'activer un interrupteur ; il s'agit d'adapter la stratégie de mise en cache à vos données spécifiques. Si vous proposez des données publiques et statiques à un public mondial, un CDN est une évidence. Mais qu'en est-il des données spécifiques à une session utilisateur qui doivent être accessibles sur plusieurs serveurs ? C'est là qu'intervient un cache distribué comme Redis brille. La véritable expertise réside dans la compréhension du cycle de vie de vos données et de la manière dont elles sont accessibles.
Ensuite, il y a la question délicate de la limitation de taux. Comment protéger votre service des abus sans exclure les utilisateurs légitimes ? L'erreur classique est d'appliquer une limite unique pour tous. Ne faites pas cela.
Une limite de taux bien conçue n'est pas seulement un gardien ; c'est un guide qui encourage une utilisation équitable tout en protégeant votre infrastructure. Elle doit ressembler à un garde-fou, pas à un mur de briques.
Une approche plus intelligente est nuancée. Commencez par établir des limites différentes pour chaque catégorie d'utilisateurs : votre plan gratuit ne doit pas offrir le même accès qu'un client entreprise payant. Allez encore plus loin en appliquant des limites plus strictes à vos points d'accès les plus coûteux. Un appel de génération de rapport complexe devrait avoir un seuil beaucoup plus bas qu'un appel simple. OBTENIR /statut Cela protège vos ressources les plus sollicitées sans pénaliser les activités normales.
Quand est-il temps de refactoriser pour évoluer ?
C'est peut-être la question la plus importante de toutes. Quand faut-il arrêter de corriger et commencer à reconstruire ? La réponse se trouve presque toujours dans vos données de surveillance. Si vos temps de réponse augmentent lentement mais sûrement, même après avoir optimisé les requêtes et ajouté des caches, c'est un signe. Si un service spécifique est constamment à 100 % de CPU pendant les heures de pointe, c'est un autre indicateur.
Vous avez probablement dépassé les limites de votre architecture actuelle lorsque vous remarquez ces signes révélateurs :
- Latence persistante : Your and Les métriques de latence restent désespérément élevées, même pour des requêtes simples et quotidiennes.
- Points de douleur géographiques : Vous commencez à recevoir des plaintes régulières concernant des performances lentes de la part d'utilisateurs situés dans des régions éloignées de vos serveurs.
- Goulots d'étranglement de scalabilité : Une seule base de données ou service atteint systématiquement ses limites de ressources à chaque pic de trafic.
Repérer ces schémas est votre signal. Cela signifie que les petits ajustements ne suffisent plus, et qu'il est temps d'investir dans une architecture plus évolutive. Cela pourrait impliquer de passer à une mise à l'échelle horizontale avec des équilibreurs de charge, de déployer votre API dans plusieurs régions, ou enfin de décomposer ce monolithe en microservices. C'est un projet de grande envergure, mais c'est le seul moyen de garantir que votre API pourra gérer une croissance à long terme tout en restant fiable.
Prêt à en finir avec le jonglage entre plusieurs API de réseaux sociaux ? LATE offre une API unique et unifiée pour programmer du contenu sur sept grandes plateformes avec 99,97 % temps de disponibilité et sous-50 ms réponses. Commencez à créer gratuitement dès aujourd'hui..