Cuando trabajas en mejorar el rendimiento de tu API, el plan de acción es bastante sencillo: reduce el tiempo de respuesta.latencyreduce el tamaño de tus cargas útiles y optimiza el almacenamiento en caché. Domina estos tres fundamentos y tendrás una API que no solo es rápida y eficiente, sino que también ofrece una experiencia confiable que mantiene a los usuarios satisfechos y a tu negocio en crecimiento.
Por qué el rendimiento de la API es más crítico que nunca
En el mundo actual, las aplicaciones están completamente interconectadas, y las APIs son los hilos que mantienen todo unido. Una API lenta o inestable no es solo un pequeño inconveniente que provoca un poco de retraso. Es un golpe directo a la retención de usuarios, la eficiencia operativa y los resultados de tu empresa. Cuando una API falla, puede generar un efecto dominó masivo, afectando a cada uno de los servicios que dependen de ella.
Solo piensa en tu aplicación de banca móvil. Si la llamada a la API para obtener el saldo de tu cuenta se demora, tu confianza en ese banco comienza a desvanecerse. O imagina un sitio de comercio electrónico donde la API del gateway de pago es lenta; esa demora se traduce directamente en carritos abandonados y ventas perdidas. Por eso, optimizar el rendimiento de las APIs ha pasado de ser una práctica técnica "opcional" a convertirse en una estrategia empresarial fundamental. La gente espera que las cosas sean instantáneas, y su paciencia para las demoras ha desaparecido casi por completo.
El Costo Real del Tiempo de Inactividad
Incluso una pequeña caída en tu porcentaje de tiempo de actividad puede tener consecuencias sorprendentemente grandes. Hemos observado datos bastante preocupantes recientemente: entrePrimer trimestre de 2024 and T1 2025, el tiempo de actividad promedio de la API en realidad disminuyó de99.66% to 99.46%0,2%"drop" puede no parecer mucho, pero se traduce en un asombrosoAumento del 60% en el tiempo total de inactividad de la API.análisis detallado. Esto se traduce en casi nueve horas adicionales de interrupciones en el servicio cada año. Si deseas profundizar en los datos por tu cuenta, puedes encontrar elanálisis completo de la fiabilidad de la API de Uptrends.
El gráfico a continuación pone en perspectiva el cambio interanual, mostrando lo difícil que se ha vuelto mantener una alta disponibilidad.

Esta visualización resalta que una disminución aparentemente pequeña en los indicadores de rendimiento puede traducirse en un tiempo de inactividad considerable en el mundo real.
"Cada milisegundo cuenta. En un mundo donde los servicios están profundamente interconectados, el rendimiento de tu API es el rendimiento de tu negocio. Una API lenta se convierte en un cuello de botella que frena el crecimiento, erosiona la confianza del cliente y le otorga una ventaja competitiva a tus rivales."
En última instancia, el objetivo no es simplemente hacer que una API sea más rápida por el mero hecho de la velocidad. Se trata de construir un servicio que sea resistente, confiable y lo suficientemente escalable para respaldar tus objetivos comerciales. Esto requiere una mentalidad proactiva que se enfoque en:
- Experiencia del Usuario:Asegurándote de que cualquier aplicación o servicio que dependa de tu API se mantenga ágil y receptivo.
- Estabilidad Operativa:Evita que un único endpoint lento provoque una reacción en cadena de fallos en tu sistema.
- Reputación Empresarial:Manteniendo la confianza tanto de tus usuarios como de los socios que dependen de tus servicios.
Ser proactivo en la mejora del rendimiento de la API no es solo una tarea técnica; es una inversión crucial en la salud y el éxito a largo plazo de toda tu operación digital.
Estrategias Fundamentales para Aumentar el Rendimiento de Forma Inmediata
Antes de que empieces a desmantelar tu arquitectura o a rehacer por completo tu pila tecnológica, hay algunos ajustes fundamentales que pueden ofrecer mejoras de rendimiento significativas. Siempre les digo a los desarrolladores que empiecen por aquí. Estas son las estrategias de alto impacto y bajo esfuerzo que funcionan como tu primera línea de defensa contra la latencia y una experiencia de usuario lenta.
Piénsalo de esta manera: si tu API es un servicio de entrega, estas estrategias son como optimizar tus rutas y reducir el tamaño de tus paquetes. Así, logras entregar más, más rápido, sin necesidad de un camión más grande.
Domina el Arte del Caching
Una de las cosas más poderosas que puedes hacer para mejorar la velocidad es simplemente dejar de hacer trabajo innecesario. Ahí es donde entra en juego la caché. La caché es la práctica de almacenar los resultados de operaciones costosas—como una consulta a una base de datos grande o un cálculo complejo—y reutilizar ese resultado para solicitudes idénticas que lleguen más tarde. En lugar de consultar a tus servidores backend cada vez por los mismos datos, sirves una copia guardada desde una caché mucho más rápida.
He visto que esto funciona de maravilla para los endpoints que sirven datos estáticos o que cambian con poca frecuencia, como perfiles de usuario, catálogos de productos o configuraciones.
Al implementar un almacenamiento en caché inteligente, no solo estás acelerando las respuestas; también estás reduciendo de manera fundamental la carga en toda tu infraestructura. Esto libera recursos valiosos para gestionar las solicitudes únicas y dinámicas que realmente requieren potencia de procesamiento.
El almacenamiento en caché efectivo se trata de elegir la herramienta adecuada para cada tarea. Diferentes situaciones requieren distintas estrategias, cada una con sus propias ventajas y desventajas.
Comparación de Estrategias de Caché y Casos de Uso
Aquí tienes un resumen rápido de las técnicas de almacenamiento en caché más comunes que he utilizado, sus puntos fuertes y lo que debes tener en cuenta.
| Estrategia de Caché | Mejor para | Pros | Cons |
|---|---|---|---|
| Caché en memoria | Datos pequeños y de acceso frecuente en un solo servidor (por ejemplo, configuraciones de la aplicación). | Tiempos de acceso extremadamente rápidos; fácil de implementar. | Limitado por la RAM del servidor; los datos se pierden al reiniciar; no se comparten entre instancias. |
| Cache Distribuido | Aplicaciones de alto tráfico con múltiples servidores que requieren un estado de caché compartido. | Escalable; resistente a fallos en un solo nodo; datos consistentes entre servicios. | Más complejo de configurar y mantener (por ejemplo, Redis, Memcached). |
| Caché CDN | Activos estáticos y respuestas de API accesibles públicamente (por ejemplo, imágenes, datos de productos públicos). | Reduce la latencia para usuarios de todo el mundo y descarga el tráfico de los servidores de origen. | Puede ser costoso; la invalidación de caché puede ser complicada; no es adecuado para datos privados. |
| Caché HTTP | Caché del lado del cliente para evitar solicitudes repetidas del mismo recurso. | Reduce el tráfico de red por completo y permite al cliente ser más eficiente. | Depende de la implementación del cliente; menor control sobre el estado de la caché. |
Elegir la estrategia adecuada, o incluso una combinación de ellas, puede marcar una gran diferencia en la percepción de la rapidez y la capacidad de respuesta de tu API para tus usuarios.
Optimiza tus cargas útiles
Otra gran fuente de latencia es el tamaño de los datos que estás enviando a través de la red. Es un hecho simple: los payloads grandes y pesados tardan más en transmitirse y más tiempo en ser procesados por el cliente. Cada campo innecesario que envías contribuye a esa demora.
Aquí tienes mis dos métodos favoritos para reducir el tamaño de los payloads:
- Compresión de Datos:Esto es pan comido. Utiliza algoritmos de compresión estándar comoGzip or Brotli. Estas herramientas pueden reducir el tamaño de las respuestas JSON o XML, a veces hasta en un70-80%La mayoría de los servidores web y clientes lo admiten de forma nativa con solo unos pocos cambios de configuración.
- Filtrado de Campos:No envíes todo el contenido si el cliente solo necesita una cucharada de azúcar. Ofrece a los clientes la posibilidad de especificar solo los campos que realmente necesitan. Este es un concepto fundamental enGraphQL, pero puedes implementar fácilmente una versión básica en una API REST con un simple
fieldsparámetro de consulta.
Solo mira el tipo de impacto que estas optimizaciones pueden tener en el tiempo de respuesta y el rendimiento.
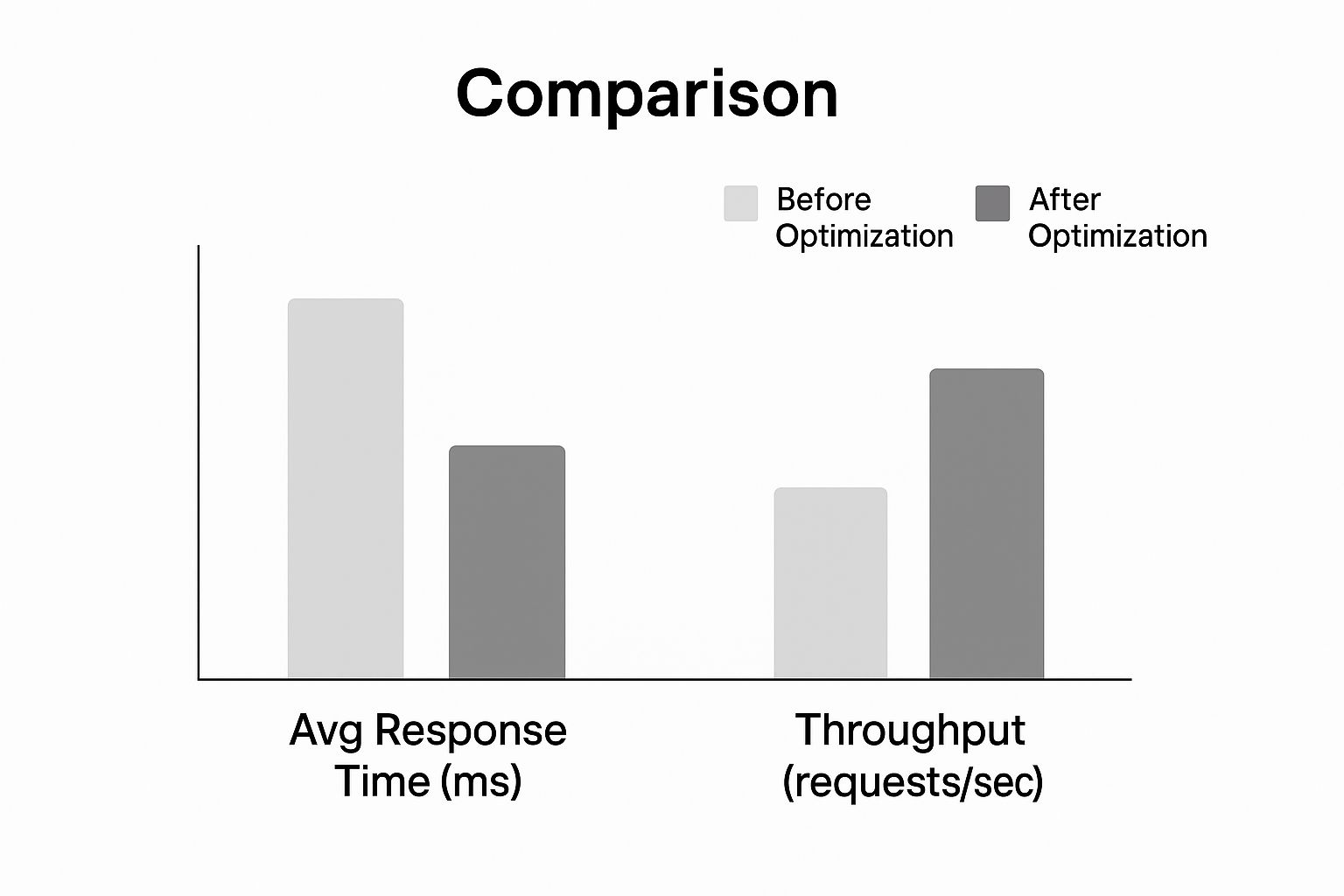
Como muestra el gráfico, aplicar estas estrategias fundamentales provoca una drástica reducción en los tiempos de respuesta, permitiendo que el API maneje un volumen de solicitudes mucho mayor. Estos dos cambios por sí solos pueden hacer que tu API se sienta notablemente más ágil.
Para profundizar en conceptos relacionados, consulta nuestra guía sobreMejores prácticas para la integración de APIAl dominar estos conceptos básicos, establecerás una sólida base de rendimiento antes de siquiera considerar enfrentar desafíos arquitectónicos más complejos.
Controla el tráfico con un límite de tasa inteligente y regulación de flujo.
Más pronto que tarde, una avalancha descontrolada de solicitudes puede llevar incluso a la API más resistente a su límite. He sido testigo de ello. Ya sea por un script descontrolado, un momento viral inesperado o un actor malicioso, el tráfico incontrolado representa una amenaza directa para la disponibilidad y el rendimiento de tu API. Por eso es fundamental implementar soluciones inteligentes.limitación de tasa and throttlingno es solo una buena idea, es algo imprescindible.
Piensa en estos controles como agentes de tránsito para tu API. Imponen reglas claras sobre cuántas solicitudes puede hacer un usuario en un período determinado, protegiendo tus servicios backend de ser sobrecargados. Esto garantiza un uso justo para todos y evita que un "vecino ruidoso" arruine la experiencia de los demás usuarios.

Una estrategia de limitación de tasas bien diseñada es tu primera línea de defensa paramejora el rendimiento de la APIbajo presión. No se trata solo de rechazar solicitudes de manera arbitraria; se trata de gestionar la capacidad con elegancia para mantener la estabilidad. Sin ello, corres el riesgo de desencadenar una serie de fallos que podrían dejar fuera de línea todo tu sistema.
Elegir el Algoritmo de Limitación Adecuado
No todas las estrategias de limitación de tasa son iguales. El algoritmo que elijas impacta directamente en la flexibilidad y equidad con la que puedes gestionar el tráfico. Vamos a desglosar los enfoques más comunes que he implementado y los compromisos reales de cada uno.
- Ventana Fija:El método más sencillo que existe. Simplemente cuenta las solicitudes de un usuario dentro de un intervalo de tiempo fijo, como100solicitudes por minuto. Aunque es fácil de configurar, puede provocar picos de tráfico en el límite de la ventana. Un usuario podría hacer100solicitudes a las 11:59:59 y otra100a las 12:00:00, duplicando efectivamente su límite.
- Ventana Deslizante:Este enfoque soluciona el problema de los picos al rastrear las solicitudes a lo largo de una ventana de tiempo continua. Te ofrece un límite de tasa mucho más preciso, pero tiene un costo: requiere más almacenamiento de datos y potencia computacional para su mantenimiento.
- Cubo de Tokens:Este es mi método preferido por su increíble flexibilidad. Cada usuario recibe un "contenedor" de tokens que se recarga a un ritmo constante. Cada solicitud a la API consume un token. Esta configuración permite ráfagas breves de tráfico (siempre que tengas tokens) pero garantiza una tasa promedio consistente a lo largo del tiempo, lo cual es excelente para la experiencia del usuario.
El algoritmo de token bucket, por ejemplo, es ideal para un servicio como LATE. Un usuario puede necesitar programar una serie de publicaciones en redes sociales de una sola vez, pero luego tener períodos más tranquilos. Este algoritmo se adapta a ese patrón de uso legítimo sin poner en riesgo la salud del sistema.
La limitación de tasas no es solo una medida defensiva; es una herramienta para moldear el comportamiento del usuario y garantizar un acceso equitativo a los recursos de tu API. Una política bien implementada mejora la equidad y la previsibilidad para todos los consumidores.
Reglas Personalizadas para Diferentes Escenarios
Un límite de tasa único no funciona en el mundo real. Para proteger realmente tu API mientras ofreces un servicio efectivo a los usuarios, necesitas ser más específico y adaptar tus reglas. Un excelente punto de partida es implementar diferentes límites según los niveles de suscripción de los usuarios.
| Nivel de Usuario | Ejemplo de Límite de Solicitudes | Caso de uso |
|---|---|---|
| Plan Gratuito | 100solicitudes/hora | Para usuarios en prueba y proyectos personales de bajo volumen. |
| Plan Básico | 1,000solicitudes/hora | Para pequeñas empresas y aplicaciones en crecimiento. |
| Nivel Empresarial | 10,000solicitudes/hora | Para clientes de alto volumen con necesidades críticas para su misión. |
Este enfoque escalonado no solo protege tu infraestructura, sino que también establece un camino claro de actualización para los usuarios a medida que crecen sus necesidades. Además, puedes ser más específico aplicando límites más estrictos a los puntos finales que consumen muchos recursos (como una búsqueda compleja en la base de datos) mientras que puedes ser más generoso con aquellos que son más ligeros (como una simple verificación de estado).
Para un análisis aún más profundo de estas estrategias, consulta nuestra guía sobreMejores prácticas para el límite de tasa de la APIAl implementar estos controles inteligentes, puedes garantizar que tu API se mantenga rápida, justa y accesible para todos.
Arquitectura para Escalabilidad y un Público Global
Cuando estás comenzando, una configuración de un solo servidor parece sencilla y cumple su función. Es ideal para una base de usuarios pequeña y local. Pero, ¿qué sucede cuando tu aplicación comienza a despegar a nivel global? Esa arquitectura que antes era confiable se convierte rápidamente en tu mayor dolor de cabeza en cuanto a rendimiento.
To mejorar el rendimiento de la APIPara una audiencia internacional en crecimiento, debes dejar de pensar en un solo servidor y comenzar a imaginar un sistema distribuido a nivel mundial.
El enemigo número uno aquí eslatencyCada solicitud de un usuario en Tokio a tu servidor en Virginia tiene que recorrer miles de millas, lo que añade cientos de milisegundos de latencia antes de que tu código comience a ejecutarse. Esta es precisamente la razón por la que unRed de Entrega de Contenidos (CDN)no es solo un lujo; es esencial. Un CDN almacena en caché las respuestas de tu API en ubicaciones "edge" alrededor del mundo, lo que significa que los usuarios reciben la información de un servidor que está geográficamente cerca, reduciendo así el tiempo de viaje de la red.
Adopta la Escalabilidad Horizontal
No se trata solo de la distancia; se trata del volumen. A medida que más usuarios acceden a tu API, necesitas una estrategia para gestionar la carga. Aquí es donde entraescalado horizontalen su lugar, añades más máquinas a tu flota, distribuyendo el trabajo entre ellas.
La magia sucede con unbalanceador de cargaEste componente se sitúa frente a tus servidores, actuando como un controlador de tráfico que dirige de manera inteligente las solicitudes entrantes hacia la máquina menos ocupada. Esto evita que un solo servidor se sature y construye una increíble resiliencia. ¿Un servidor falla? No hay problema. El balanceador de carga simplemente redirige el tráfico a los servidores saludables, manteniendo tu API en línea.
Esta estrategia es ideal para unarquitectura de microserviciosAl dividir tu gran aplicación en pequeños servicios independientes, puedes escalar solo las partes que lo necesiten. Por ejemplo, si tu servicio de inicio de sesión de usuarios está recibiendo una gran carga durante las horas pico, puedes lanzar más instancias de ese servicio sin afectar nada más.
Diseñar para escalar no se trata solo de manejar más tráfico; se trata de construir un sistema resiliente y adaptable. Al distribuir tanto tus datos como tus recursos de cómputo, creas una API que es inherentemente más rápida y confiable para cada usuario, sin importar dónde se encuentren.
Construyendo una Huella Global Resiliente
Pasar a una arquitectura distribuida casi siempre implica dejar atrás los servidores locales en favor de un entorno en la nube flexible que pueda crecer contigo. Diseñar para una audiencia global significa acertar con tu infraestructura desde el principio. Si eres nuevo en esta transición, profundizar en unguía experta para migrar servidores a la nubepuede ser de gran ayuda.
Aquí están los elementos clave para construir una presencia global sólida:
- Puntos de acceso regionales:No te limites a una sola implementación. Crea instancias de tu API en múltiples regiones geográficas como América del Norte, Europa y Asia. Esto te permite dirigir a los usuarios a la más cercana, reduciendo drásticamente la latencia.
- Replicación de Bases de Datos:Una única base de datos puede convertirse en un gran cuello de botella. Utilizaréplicas de lecturaen diferentes regiones para ofrecer datos de manera local. Esto acelera las operaciones que requieren mucha lectura para los usuarios que se encuentran lejos de tu base de datos principal.
- Verificaciones de Salud:Configura tu balanceador de carga para que realice pings constantes a tus servidores y verifique su estado de salud. Si alguna instancia deja de responder, el balanceador de carga la retirará automáticamente de la rotación, evitando que los usuarios vean errores.
Al combinar estas estrategias, creas un sistema potente y multidimensional. La CDN gestiona el primer punto de contacto, el balanceador de carga distribuye el trabajo y los despliegues regionales aseguran que el procesamiento ocurra lo más cerca posible del usuario. Este es el modelo a seguir para cualquier API que busque atender a una audiencia global en crecimiento sin contratiempos.
El impacto de la automatización y la inteligencia artificial en el rendimiento de las API
No es un secreto que la inteligencia artificial ha transformado por completo nuestro panorama digital. Cada chatbot, cada herramienta de análisis de datos, cada nueva función impulsada por IA depende de una red de APIs para funcionar. Esto ha desatado un torrente de tráfico que los sistemas antiguos, gestionados manualmente, simplemente no están preparados para manejar.
No estamos hablando solo de un pequeño aumento en las solicitudes. Es todo un nuevo paradigma. Esta explosión impulsada por la inteligencia artificial ha provocado un asombroso73%un aumento en las llamadas a APIs relacionadas con la inteligencia artificial a nivel mundial, lo que está generando una presión increíble sobre la infraestructura para mantenerse al día. Por eso, las plataformas de generación automática de APIs, que pueden reducir el tiempo de desarrollo en aproximadamente85%se están volviendo tan esenciales. Puedes leer más sobre cómoEl auge de las API de IA refuerza esta necesidad de automatización en blog.dreamfactory.com.

Superando el desarrollo manual
En esta nueva realidad, la antigua forma de hacer las cosas—construir, implementar y gestionar cada API de manera manual—es un callejón sin salida. Los procesos manuales son lentos, están plagados de posibilidades de error humano y simplemente no pueden moverse a la velocidad que exige la inteligencia artificial. Intentar gestionar esta complejidad a mano genera enormes cuellos de botella que ahogan el rendimiento y la innovación.
La automatización ya no es un "extra"; es una necesidad estratégica. Al automatizar todo el ciclo de vida de la API—desde la creación y las pruebas hasta el despliegue y la supervisión—construyes servicios que son más resilientes, seguros y escalables desde el principio.
El objetivo no es solo construir APIs más rápido. Se trata de integrar el rendimiento y la seguridad directamente en el proceso de desarrollo, asegurando que tu infraestructura pueda soportar las intensas demandas de la era de la IA sin necesidad de intervención manual constante.
La automatización de la gestión de API te permite concentrarte en lo que realmente importa: ofrecer valor. Cuando no estás atrapado en el día a día del mantenimiento repetitivo, puedes innovar. Un excelente ejemplo en la vida real es optimizar el alcance con unAPI de automatización de marketing.
La Ventaja Estratégica de la Generación Automatizada
El auge de la inteligencia artificial también nos ha proporcionado herramientas que simplifican el desarrollo del backend. Si indagas más a fondo, verás cómosoluciones de IA para backend sin códigoestán transformando por completo el panorama. Estas plataformas llevan la automatización a otro nivel al generar APIs de alta calidad listas para producción con muy poco código manual.
Este enfoque te ofrece varias ventajas importantes paramejorando el rendimiento de la API:
- Despliegue Acelerado:Los equipos pueden lanzar nuevas APIs en una fracción del tiempo que tomarían los métodos tradicionales. Esto te permite reaccionar rápidamente a los cambios del mercado.
- Prácticas recomendadas integradas:Estas plataformas incorporan de forma predeterminada elementos esenciales como la seguridad OAuth, la limitación de tasas y el almacenamiento en caché. Esto cierra brechas de seguridad comunes antes de que puedan convertirse en un problema.
- Escalabilidad Consistente:Las APIs generadas de esta manera suelen estar construidas desde el principio sobre arquitecturas escalables, listas para manejar el tráfico impredecible que los servicios de IA pueden generar.
En última instancia, no puedes permitirte ignorar la automatización y la inteligencia artificial en tu estrategia de API. Es la forma más práctica de construir y mantener la infraestructura de alto rendimiento, segura y escalable que necesitas para competir en la actualidad.
Preguntas Frecuentes sobre el Rendimiento de la API
Al comenzar a profundizar en el rendimiento de la API, notarás que las mismas preguntas surgen una y otra vez. He visto que incluso equipos experimentados se quedan atascados con ellas. Resolver estas cuestiones es la clave para distinguir entre una API que simplemente funciona y una que es realmente rápida y resistente.
Vamos a abordar algunos de los más importantes.
Primero, hablemos de la caché. Todos saben que...shouldcaché, pero la verdadera pregunta eshowNo se trata solo de activar un interruptor; se trata de adaptar la estrategia de almacenamiento en caché a tus datos específicos. Si estás ofreciendo datos públicos y estáticos a una base de usuarios global, unCDNes una solución evidente. Pero, ¿qué pasa con los datos que son específicos de una sesión de usuario y que necesitan ser accesibles a través de múltiples servidores? Ahí es donde entra en juego un caché distribuido comoRedisbrilla. La verdadera experiencia radica en comprender el ciclo de vida de tus datos y cómo se accede a ellos.
Luego está el complicado tema de la limitación de tasas. ¿Cómo proteges tu servicio del abuso sin excluir a los usuarios legítimos? El error común es aplicar un límite único para todos. No hagas eso.
Un límite de tasa bien diseñado no es solo un guardián; es una guía que fomenta un uso justo mientras protege tu infraestructura. Debe sentirse como una barandilla, no como un muro de ladrillos.
Un enfoque más inteligente es matizado. Comienza estableciendo diferentes límites para los distintos niveles de usuarios: tu plan gratuito no debería tener el mismo acceso que un cliente empresarial que paga mucho. Hazlo aún más específico aplicando límites más estrictos a tus puntos finales más costosos. Una llamada para generar informes complejos debería tener un umbral mucho más bajo que una simple.OBTENER /estadoEsto protege tus recursos más críticos sin penalizar la actividad normal.
¿Cuándo es el momento de refactorizar para escalar?
Esta podría ser la pregunta más importante de todas. ¿Cuándo dejas de hacer parches y comienzas a reconstruir? La respuesta casi siempre está en tus datos de monitoreo. Si tus tiempos de respuesta están aumentando lenta pero seguramente, incluso después de haber optimizado consultas y añadido cachés, es una señal. Si un servicio específico está constantemente al 100% de CPU durante las horas pico, eso es otra señal.
Probablemente has superado la capacidad de tu arquitectura actual cuando observes estas señales reveladoras:
- Latencia Persistente: Your and Las métricas de latencia son notablemente altas, incluso para solicitudes simples y cotidianas.
- Puntos de Dolor Geográficos:Comienzas a recibir quejas constantes sobre el rendimiento lento de los usuarios en regiones específicas que están lejos de tus servidores.
- Cuellos de botella en la escalabilidad:Una única base de datos o servicio alcanza constantemente su límite de recursos cada vez que hay un aumento en el tráfico.
Identificar estos patrones es tu señal. Significa que los pequeños ajustes ya no son suficientes y es momento de invertir en una arquitectura más escalable. Esto podría implicar pasar a un escalado horizontal con balanceadores de carga, desplegar tu API en múltiples regiones o, finalmente, descomponer ese monolito en microservicios. Es un esfuerzo considerable, pero es la única forma de garantizar que tu API pueda manejar el crecimiento a largo plazo y seguir siendo confiable.
¿Listo para dejar de hacer malabares con múltiples APIs de redes sociales?LATEofrece una API única y unificada para programar contenido en siete plataformas principales con99.97%tiempo de actividad y sub-50 msComienza a construir gratis hoy mismo..